Vortrag am 19.Mai 2015 im Literaturhaus Frankfurt in der Veranstaltung PR-Slam & Ham 2015
In meiner Präsentation hatte ich eine Reihe von Schaubildern gezeigt, die ich dann mündlich kommentiert habe. Einen geschriebenen Text gab es nicht. Ich habe aber die Erläuterung nochmals ’nachgesprochen‘. Aus den 20 Min sind dann ca. 70 Min geworden. Die Bilder unten bilden das Rückgrat der Geschichte; sie sind nummeriert. Im gesprochenen Text nehme ich auf diese Bilder Bezug.
Das Ganze endet in einem glühenden Plädoyer für die Zukunft des Lebens in Symbiose mit einer angemessenen Technik. Wir sind nicht das ‚Endprodukt‘ der Evolution, sondern nur eine Durchgangsstation hin zu etwas ganz anderem!
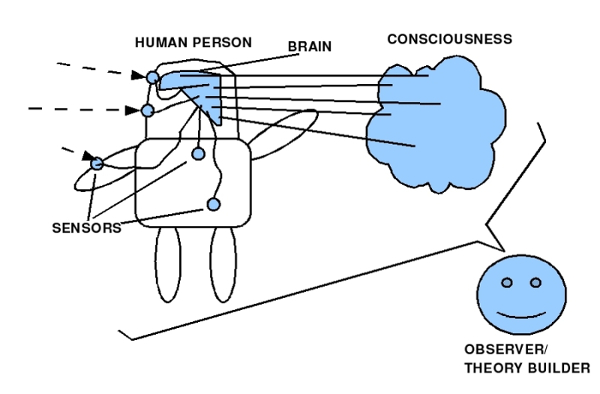
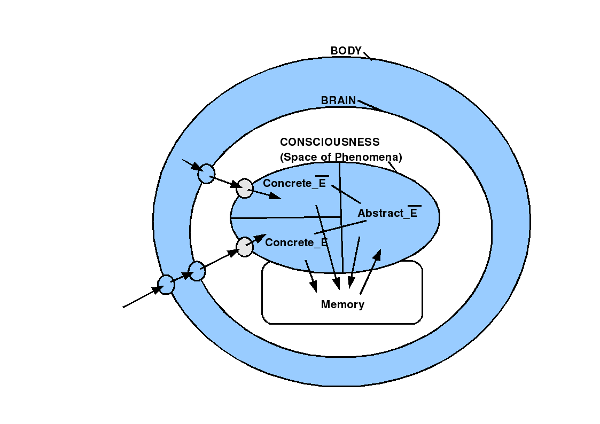
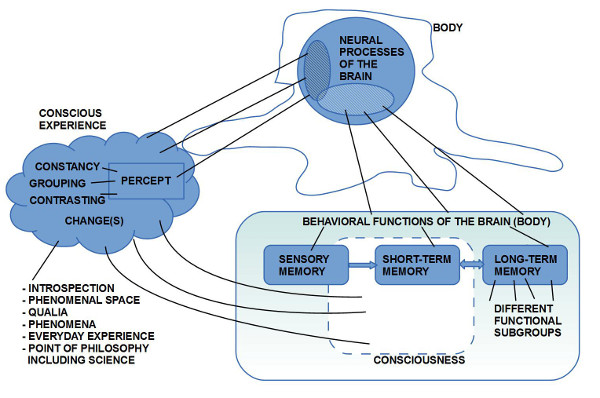
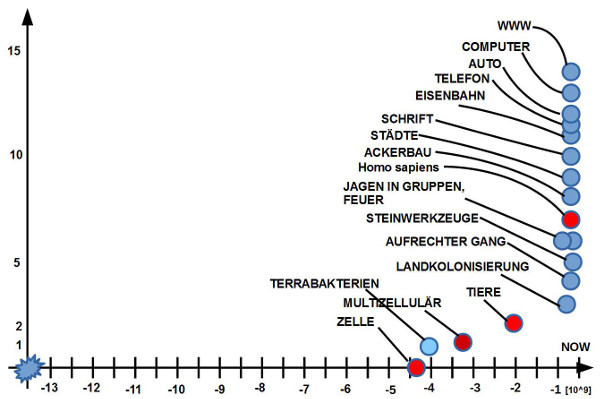
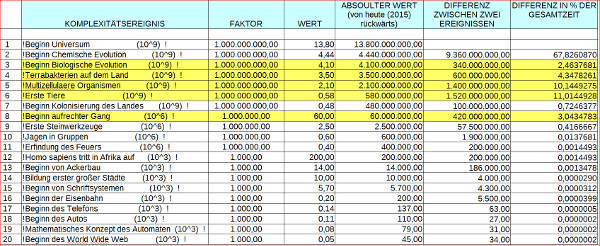
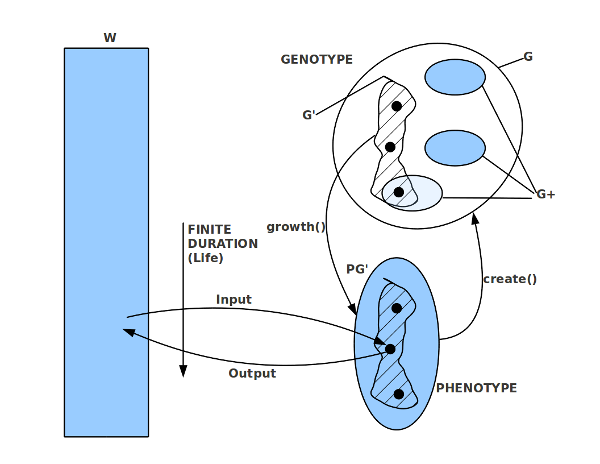
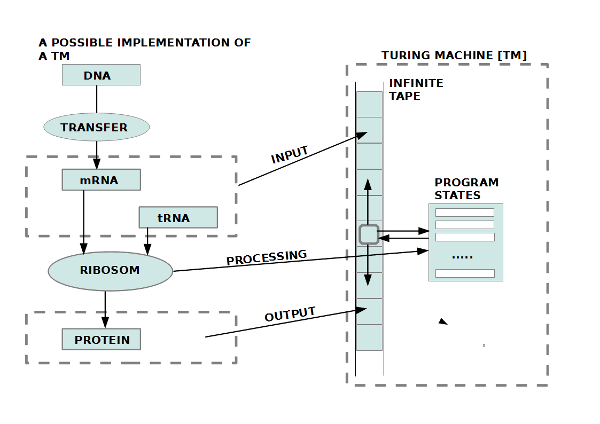
Bild 1: Gehirn im Körper mit Bewusstsein – Beobachter Bild 2: Gehirn im Körper mit Raum der Phänomene. Empirische und nicht-empirische Phänomene Bild 3: Korrelation zwischen Gehirn, Bewusstsein und Gedächtnis. Gedächtnis mit Sensorik, Arbeitsgedächtnis und Langzeitgedächtnis Bild 4: Mensch im Alltag, umringt von technischen Schnittstellen die mit digitalisierten weltausschnitten verbinden können: viel. schnell, komplex Bild 5: Menge von Komplexitätsereignissen bisher; Explosion in der Gegenwart Bild 6: Konkrete Zahlen zum vorhergehenden Schaubild mit den Komplexitätsereignissen Bild 7: Biologischer Reproduktion als Quelle der Kreativität für neue Strukturen Bild 8: Struktur der biologischen Reproduktion in 1-zu-1 Isomorphie zur Struktur eines Automaten (Turingmaschine)
Die Vision, die in dem Audiobeitrag gegen Ende entwickelt wird, soll in dem Emerging-Mind Projekt konkret umgesetzt werden, als Impuls, als Anstoß, als Provokation, als Community, die sich mit dem Thema philosophisch, wissenschaftlich, künstlerisch und theologisch auseinandersetzt.
Eine Übersicht über alle Einträge von cagent in diesem Blog nach Titeln findet sich HIER.
Begriffsnetzwerk von der Philosophiewerkstatt am 10.Mai 2015
Generelles Anliegen der Philosophiewerkstatt ist es, ein philosophisches Gespräch zu ermöglichen, in dem die Fragen der TeilnehmerInnen versuchsweise zu Begriffsnetzen verknüpft werden, die in Beziehung gesetzt werden zum allgemeinen Denkraum der Philosophie, der Wissenschaften, der Kunst und Religion. Im Hintergrund stehen die Reflexionen aus dem Blog cognitiveagent.org, das Ringen um das neue Menschen- und Weltbild.
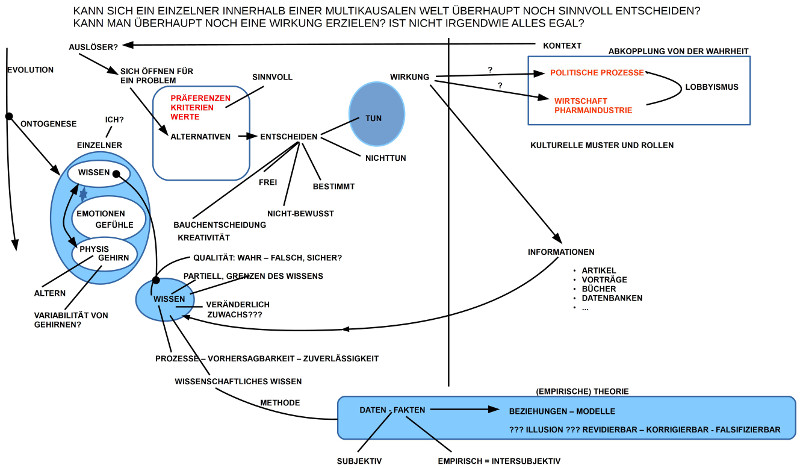
Aus der letzten Philosophiewerkstatt vom 12.April 2015 resultierte das – nicht ganz schar formulierte – Thema: Kann sich ein einzelner innerhalb einer multikausalen Welt überhaupt noch sinnvoll entscheiden? Kann man überhaupt noch eine Wirkung erzielen? Ist nicht irgendwie alles egal?
1. Trotz strahlendem Sommerwetter fand sich wieder ein bunter Kreis interessierter und engagierter Gesprächsteilnehmer, um sich in der DENKBAR Frankfurt zum Thema auszutauschen. Wie beim jedem Treffen bisher gab es auch dieses Mal neben schon bekannten Teilnehmern wieder auch neue Teilnehmer, die das Gespräch bereicherten.
2. Wie die Gedankenskizze des Gesprächs andeutet, förderte das gemeinsame Gespräch eine Fülle interessanter Aspekte zutage, die auf vielfältige Weise miteinander verknüpft sind. Auch wenn jeder Punkt für sich ein eigenes Thema abgeben könnte, so zeigt gerade der Überblick über und die Vernetzung von den Begriffen etwas von unserer Entscheidungswirklichkeit auf, die im Alltag oft im Dunkeln verbleibt.
INDIVIDUUM – KONTEXT
3. Das Gespräch fokussierte zunächst eher auf den individuellen Träger von Entscheidungen und lies die diverse Einflüsse des Kontextes eher am Rande.
4. Am Entscheidungsprozess traten verschieden ‚Phasen‘ hervor: (i) irgendein ein Anlass. Warum man sich überhaupt mit etwas beschäftigt. Warum öffnet man sich überhaupt für ein Thema? Wendet man sich einem Thema zu, dann gibt es in der Regel mindestens eine Alternative, was man tun könnte. Dies hängt sowohl von den konkreten Umständen wie auch von der verfügbaren Erfahrung und dem verfügbaren Wissen ab. Nach welchen Kriterien/ Präferenzen/ Werten entscheidet man dann, welche der vielen Möglichkeiten man wählen soll? Ist die Entscheidung ‚frei‘ oder durch irgendwelche Faktoren ‚vorbestimmt‘? Gibt es explizite Wissensanteile, aufgrund deren man meint, ‚rational‘ zu handeln, oder ist es eine ‚Bauchentscheidung‘? Wieweit spielen ’nicht-bewusste‘ Anteile mit hinein? Insofern nicht-bewusste Anteile von sich aus nicht bewusst sind, können wir selbst dies gar nicht wissen. Wir bräuchten zusätzliche Hilfen, um dies möglicherweise sichtbar zu machen. Schließlich wurde bemerkt, dass selbst dann, wenn wir sogar zu einer Entscheidung gekommen sind, was wir tun sollten, es sein kann, dass wir die Ausführung lassen. Wir tun dann doch nichts. Sollten wir etwas tun, dann würde unser Tun ‚eine Wirkung‘ entfalten.
ARCHITEKTUR DES INDIVIDUUMS
5. Alle diese Entscheidungsprozesse verlaufen in einer Person; im anderen, in mir. Wir wissen, dass jeder Mensch eine komplexe Architektur besitzt, sehr viele unterschiedliche Komponenten besitzt, die in Wechselwirkung stehen. Folgende drei Bereich wurden genannt, ohne Anspruch auf Vollständigkeit: (i) der Körper selbst, die Physis, das Physiologische. Das Gehirn ist eines der vielen komplexen Organe im Bereich der Physis. Das Physische kann altern, kann zwischen Menschen Varianzen aufweisen. Resultiert aus einem individuellen Wachstumsprozess (Ontogenese), und im Rahmen einer Population resultiert der Bauplan eines individuellen Körpers aus einem evolutionären Prozess (Phylogenese). Sowohl in der Phylogenese wie in der Ontogenese können sich Strukturen umweltabhängig, verhaltensabhängig und rein zufällig verändern. Weiter gibt es (ii) den Komplex, der grob mit Emotionen, Gefühle umschrieben wurde. Es sind Körper- und Gemütszustände, die auf das Bewerten der Wahrnehmung und das Entscheiden Einfluss ausüben können (und es in der Regel immer tun). Schließlich (iii) gibt es den Komplex Wissen/ Erfahrung, der Menschen in die Lage versetzt, die Wahrnehmung der Welt zu strukturieren, Beziehungen zu erkennen, Beziehungen herzustellen, komplexe Muster aufzubauen, usw. Ohne Wissen ist ein Überschreiten des Augenblicks nicht möglich.
WISSEN
6. Aufgrund der zentralen Rolle des Wissens ist es dann sicher nicht verwunderlich, dass es zum Wissen verschiedene weitere Überlegungen gab.
7. Neben der Betonung der zentralen Rolle von Wissen wurde mehrfach auf potentielle Grenzen und Schwachstellen hingewiesen: (i) gemessen an dem objektiv verfügbare Wissen erscheint unser individuelles Wissen sehr partiell, sehr begrenzt zu sein. Es ist zudem (ii) veränderlich durch ‚Vergessen‘ und ‚Neues‘. Auch stellte sich die Frage (iii) nach der Qualität: wie sicher ist unser Wissen? Wie ‚wahr-falsch‘? Woher können wir wissen, ob das, was wir ‚für wahr halten‘, an was wir ‚glauben‘, tatsächlich so ist? Dies führte (iv) zu einer Diskussion des Verhältnisses zwischen ‚wissenschaftlichem‘ Wissen und ‚Alltags-‚ bzw. ‚Bauchwissen‘. Anwesende Ärzte betonten, dass sie als Arzt natürlich nicht einfach nach ‚Bauchwissen‘ vorgehen könnten, sondern nach explizit verfügbarem wissenschaftlichen Wissen. Im Gespräch deutete sich dann an, dass natürlich auch dann, wenn jemand bewusst nach explizit vorhandenem Wissen vorgehen will, er unweigerlich an die ‚Ränder seines individuellen‘ Wissens stoßen wird und dass er dann gar keine andere Wahl hat, als nach zusätzlichen (welche!?) Kriterien zu handeln oder – was vielen nicht bewusst ist – sie ‚verdrängen‘ die reale Grenze ihres Wissens, indem sie mögliche Fragen und Alternativen ‚wegrationalisieren‘ (das ‚ist nicht ernst‘ zu nehmen, das ist ‚unwichtig‘, das ‚machen wir hier nicht so‘, usw.). Ferner wurde (v) der Status des ‚wissenschaftlichen‘ Wissens selbst kurz diskutiert. Zunächst einmal beruht die Stärke des wissenschaftlichen Wissens auf einer Beschränkung: man beschäftigt sich nur mit solchen Phänomenen, die man ‚messen‘ kann (in der Regel ausschließlich intersubjektive Phänomene, nicht rein subjektive). Damit werden die Phänomene zu ‚Fakten‘, zu ‚Daten‘. Ferner formuliert man mögliche Zusammenhänge zwischen den Fakten in expliziten Annahmen, die formal gefasst in einem expliziten Modell repräsentiert werden können. Alle diese Modelle sind letztlich ‚Annahmen‘, ‚Hypothesen‘, ‚Vermutungen‘, deren Gültigkeit von der Reproduzierbarkeit der Messungen abhängig ist. Die Geschichte der Wissenschaft zeigt überdeutlich, dass diese Modelle beständig kritisiert, widerlegt und verbessert wurden. Wissenschaftliches Wissen ist insofern letztlich eine Methode, wie man der realen Welt (Natur) schrittweise immer mehr Zusammenhänge entlockt. Die ‚Sicherheit‘ dieses Wissens ist ‚relativ‘ zu den möglichen Messungen und Modellen. Ihre Verstehbarkeit hängt zudem ab von den benutzten Sprachen (Fachsprachen, Mathematische Sprachen) und deren Interpretierbarkeit. Die moderne Wissenschaftstheorie konnte zeigen, dass letztlich auch empirische Theorien trotz aller Rückbindung auf das Experiment ein Bedeutungsproblem haben, das sich mit der Fortentwicklung der Wissenschaften eher verschärft als vereinfacht. Im Gespräch klang zumindest kurz an (vi), dass jedes explizites Wissen (auch das wissenschaftliche), letztlich eingebunden bleibt in das Gesamt eines Individuums. Im Individuum ist jedes Wissen partiell und muss vom Individuum im Gesamtkontext von Wissen, Nichtwissen, Emotionen, körperlicher Existenz, Interaktion mit der Umwelt integriert werden. Menschen, die ihr Wissen wie ein Schild vor sich hertragen, um damit alles andere abzuwehren, zu nivellieren, leben möglicherweise in einer subjektiven Täuschungsblase, in der Rationalität mutiert zu Irrationalität.
UND DEN KONTEXT GIBT ES DOCH
8. Schließlich gewann der Kontext des Individuums doch noch mehr an Gewicht.
9. Schon am Beispiel des wissenschaftlichen Wissens wurde klar, dass Wissenschaft ja keine individuelle Veranstaltung ist, sondern ein überindividuelles Geschehen, an dem potentiell alle Menschen beteiligt sind.
10. Dies gilt auch für die schier unendlich erscheinende Menge des externen Wissens in Publikationen, Bibliotheken, Datenbanken, Internetservern, die heute produziert, angehäuft wird und in großen Teilen abrufbar ist. Dazu die verschiedenen Medien (Presse, Radio, Fernsehen, Musikindustrie,….), deren Aktivitäten um unsere Wahrnehmung konkurrieren und deren Inhalt, wenn wir es denn zulassen, in uns eindringen. Die Gesamtheit dieser externen Informationen kann uns beeinflussen wie auch ein einzelner dazu beitragen kann, diese Informationen zu verändern.
11. Es kam auch zur Sprache, dass natürlich auch die unterschiedliche Lebensstile und Kulturen spezifisch auf einzelne (Kinder, Jugendliche, Erwachsene…) einwirken bis dahin, dass sie deutliche Spuren sogar im Gehirn (und in den Genen!) hinterlassen, was sich dann auch im Verhalten manifestiert.
12. Besonders hervorgehoben wurden ferner die politischen Prozesse und Teil des Wirtschaftssystems. Die Meinung war stark vertreten, dass wir auch in den Demokratien eine ‚Abkopplung‘ der politischen Prozesse von der wählenden Bevölkerung feststellen können. Der intensive und gesetzmäßig unkontrollierte Lobbyismus im Bereich deutscher Parteien scheint ein Ausmaß erreicht zu haben, das eine ernste Gefahr für die Demokratie sein kann. Die Vertretung partikulärer Interessen (genannt wurde beispielhaft die Pharmaindustrie, aber auch Finanzindustrie und weitere), die gegenläufig zum Allgemeinwohl sind, wurde – anhand von Beispielen – als übermächtiges Wirkprinzip der aktuellen Politik unterstellt. Sofern dies tatsächlich zutrifft, ist damit natürlich die sowieso schon sehr beschränkte Einflussmöglichkeit des Wählers weitgehend annulliert. Die zu beobachtende sich verstärkende Wahlmüdigkeit des Wählers wird damit nur weiter verstärkt. Das Drama ist, dass diejenigen, die das Wählervertrauen durch ihr Verhalten kontinuierlich zerstören, nämlich die gewählten Volksvertreter, den Eindruck erwecken, dass sie selbst alles verhindern, damit der extreme Lobbyismus durch Transparenz und wirksamen Sanktionen zumindest ein wenig eingedämmt wird.
ABSCHLUSS
13. In der abschließenden Reflexion bildete sich die Meinung, dass die Punkte (i) Präferenzen/ Werte/ Kriterien einerseits und (ii) Beeinflussbarkeit politischer Prozesse andererseits in der nächsten (und letzten Sitzung vor der Sommerpause) etwas näher reflektiert werden sollten. Reinhard Graeff erklärte sich bereit, für die nächste Sitzung am So 14.Juni einen Einstieg vorzubereiten und das genaue Thema zu formulieren.
AUSBLICK
14. Am So 14.Juni 2015 16:00 findet nicht nur die letzte Sitzung der Philosophiewerkstatt vor der Sommerpause statt, sondern es soll im Anschluss auch (ca. ab 19:00h) bei Essen und Trinken ein wenig darüber nachgedacht werden, wie man in die nächste Runde (ab November 2015) einsteigen möchte. Soll es überhaupt weitergehen? Wenn ja, was ändern? Usw.
Einen Überblick über alle Beiträge zur Philosophiewerkstatt nach Themen findet sich HIER
2. Mittlerweile bildet sich ein ’spezifischer Stil‘ in der Philosophiewerkstatt heraus: Immer weniger vorgefertigter Input durch einen Eingangsvortrag, sondern stattdessen von Anfang an ein ‚gemeinsames Denken‘ entlang einer Fragestellung. Das ‚Gemeinsame‘ wird in einem aktuellen ‚Gedankenbild‘ festgehalten, ‚visualisiert‘, so dass die Vielfalt der Gedanken für alle sichtbar wird. Nichts geht verloren. Dies eröffnet dann jedem die Möglichkeit, anhand der sichtbaren Unterschiede, Lücken und Gemeinsamkeiten ‚fehlende Stücke‘ zu suchen, zu ergänzen, oder vorhandene Begriffe weiter zu erläutern.
3. Als ‚Rhythmus‘ des gemeinsamen Denkens erweist sich ein gemeinsamer Einstieg, dann ‚Blubberpause‘, dann Schlussrunde als sehr produktiv.
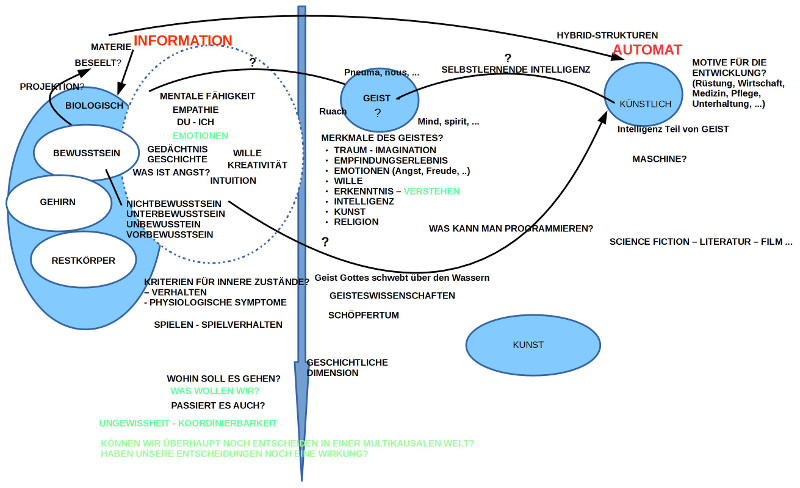
GEIST – BIOLOGISCH UND KÜNSTLICH
4. Ausgangspunkt waren die Begriffe ‚Geist‘, ‚Biologisch‘ sowie ‚Künstlich‘.
5. Auf einer Zeitachse betrachtet kann man grob sagen, dass der Begriff ‚Geist‘ in der antiken griechischen Philosophie eine zentrale Rolle gespielt hat, sich bis mindestens ins 19.Jahrhundert durchgehalten hat, dann aber – zumindest im Bereich der Naturwissenschaft – nahezu jegliche Verwendung verloren hat. In den heutigen Naturwissenschaften herrscht der Eindruck vor, man bräuchte den Begriff ‚Geist‘ nicht mehr. Zugleich fehlen damit auch alle ‚Unterstützungsmerkmale‘ für jenes Wertesystem, das einer demokratischen Staatsform wie der deutschen Demokratie zugrunde liegt. ‚Menschenwürde‘ in Art.1 des Grundgesetzes hat im Lichte der aktuellen Naturwissenschaften keine Bedeutung mehr.
6. Gleichfalls auf der Zeitachse beobachten wir, dass das Paradigma der ‚Maschine‘ mit dem Aufkommen des theoretischen Begriffs des Automaten (erste Hälfte des 20.Jahrhunderts) und der Bereitstellung von geeigneter Technologie (Computer) einen neuen Begriff von ‚Künstlichkeit‘ ermöglicht: der Computer als programmierbare Maschine erlaubt die Nachbildung von immer mehr Verhaltensweisen, die wir sonst nur von biologischen Systemen kennen. Je mehr dies geschieht, umso mehr stellt sich die Frage, wieweit diese neue ‚Künstlichkeit‘ letztlich alle ‚Eigenschaften‘ des Biologischen, insbesondere auch ‚intelligentes Verhalten‘ bzw. den ‚Geist im Biologischen‘ nachbilden kann?
GEIST – SUBJEKTIV UND OBJEKTIV NEURONAL
7. Im Bereich des Biologischen können wir seit dem 20.Jahrhundert auch zunehmend differenzieren zwischen der subjektiven Dimension des Geistes im Bereich unseres Erlebens, des Bewusstseins, und den körperlichen, speziell neuronalen Prozessen im Gehirn, die mit den subjektiven Prozessen korrelieren. Zwar ist die ‚Messgenauigkeit‘ sowohl des Subjektiven wie auch des Neuronalen noch nicht besonders gut, aber man kann schon erstaunlich viele Korrelationen identifizieren, die sehr vielen, auch grundsätzlichen subjektiv-geistigen Phänomenen auf diese Weise neuronale Strukturen und Prozesse zuordnen, die zur ‚Erklärung‘ benutzt werden können. Sofern man dies tun kann und es dann auch tut, werden die subjektiv-geistigen Phänomene in die Sprache neuronaler Prozesse übersetzt; damit wirken diese subjektiven Begriffe leicht ‚obsolet‘, ‚überflüssig‘. Zugleich tritt damit möglicherweise eine Nivellierung ein, eine ‚Reduktion‘ von spezifischen ‚Makrophänomenen‘ auf unspezifische neuronale Mechanismen, wie sie sich in allen Lebewesen finden. Erklärung im Stil von Reduktion kann gefährlich sein, wenn man damit interessante Phänomene ‚unsichtbar‘ macht, die eigentlich auf komplexere Mechanismen hindeuten, als die ‚einfachen‘ Bestandteile eines Systems.
MATERIE – INFORMATION1 und INFORMATION2
8. Im Bereich der materiellen Struktur unseres Universums hat es sich eingebürgert, dass man die physikalische Entropie mit einem Ordnungsbegriff korreliert und darüber auch mit dem statistischen Informationsbegriff von Shannon. Ich nenne diesen Informationsbegriff hier Information1.
9. Davon zu unterscheiden ist ein anderer Informationsbegriff – den ich hier Information2 nenne –, der über die Statistik hinausgeht und eine Abbildung impliziert, nämlich die Abbildung von einer Struktur auf eine andere. Im Sinne der Semiotik (:= allgemeine Lehre von den Zeichen) kann man dies als eine ‚Bedeutungsbeziehung‘ deuten, für die es auch den Begriff ’semantische Beziehung‘ gibt. Für die Realisierung einer Bedeutungsbeziehung im Sinne von Information2 benötigt man im physikalischen Raum minimal drei Elemente: eine Ausgangsgröße, eine Zielgröße und eine ‚vermittelnde Instanz‘.
10. Im Falle der Selbstreproduktion der biologischen Zellen kann man genau solch eine Struktur identifizieren: (i) die Ausgangsgröße sind solche Moleküle, deren physikalische Eigenschaften ‚für den Vermittler‘ als ‚Informationen2‘ gedeutet werden können; (ii) die Zielgröße sind jene Verbindungen von Molekülen, die generiert werden sollen; (iii) die vermittelnde Instanz sind jene Moleküle, die die Moleküle mit Information2 ‚lesen‘ und dann die ‚Generierungsprozesse‘ für die Zielgrößen anstoßen. Dies ist ein komplexes Verhalten, das sich aus den beteiligten Elementen nicht direkt ableiten lässt. Nur auf den Prozess als solchen zu verweisen, ‚erklärt‘ in diesem Fall eigentlich nichts.
11. Interessant wird dies nun, wenn man bedenkt, dass das mathematische Konzept, das den heutigen Computern zugrunde liegt, der Begriff des programmierten Automaten, ebenfalls solch eine Struktur besitzt, die es ermöglicht, Information2 zu realisieren.
12. Dies bedeutet, dass sowohl der ‚Kern‘ des Biologischen wie auch der ‚Kern‘ des neuen Künstlichen beide die Grundstruktur von Information2 repräsentieren.
13. Sofern nun das ‚Lebendige‘, das ‚Geistige‘ reduzierbar sind auf eine Information2-fähige Struktur, müsste man nun folgern, dass die Computertechnologie das gleiche Potential besitzt wie das Biologische.
OFFENE FRAGEN
14. Offen bleibt – und blieb bei dem Werkstattgespräch –, ob diese Reduktion tatsächlich möglich ist.
15. Die Frage, ob eine reduktionistische Erklärungsstrategie ausreichend und angemessen ist, um die komplexen Phänomene des Lebens zu deuten, wird schon seit vielen Jahren diskutiert.
16. Eine reduktionistische Erklärungsstrategie wäre ‚unangemessen‘, wenn man sagen könnte/ müsste, dass die Angabe einer Verhaltensfunktion f: I –-> O auf der Basis der beobachteten Reaktionen (Input I, Output O) eines Systems ‚Eigenschaften des Systems‘ sichtbar macht, die sich durch die bekannten Systembestandteile als solche nicht erklären lassen. Dies gilt verstärkt, wenn die Bestandteile eines Systems (z.B.die physikalischen Gatter im Computer oder die Neuronen im Gehirn) von sich aus keinerlei oder ein rein zufälliges Verhalten zeigen, es sei denn, man würde – im Falle des Computers – ‚in‘ die Menge der Gatter eine ‚Funktion‘ ‚hineinlegen‘, die dazu führt, dass sich die Gatter in dieser bestimmten Weise ‚verhalten‘. Würde man nun dieses spezifische Verhalten dadurch ‚erklären‘ wollen, dass man einfach die vorhandenen Gatter verweist, würde man gerade nicht erklären, was zu erklären wäre. Überträgt man diesen Befund auf biologische oder generell physikalische Systeme, dann müsste man mindestens mal die Frage stellen, ob man mit den reduktionistischen Strategien nicht genau das vernichtet, was man erklären sollte.
17. Eine Reihe von Physikern (Schrödinger, Davis) haben das Auftreten von Information2 im Kontexte des Biologischen jedenfalls als eigenständiges Phänomen gewürdigt, das man nicht einfach mit den bekannten physikalischen Erklärungsmodellen ‚erklären‘ kann.
AUSBLICK PHILOSOPHIEWERKSTATT MAI UND JUNI
18. Die nächste Philosophiewerkstatt am 10.Mai 2015 will sich der Frage widmen, wie ein einzelner innerhalb einer multikausalen Welt überhaupt noch sinnvoll entscheiden kann. Speziell auch die Frage, welche Wirkung man überhaupt noch erzielen kann? Ist nicht irgendwie alles egal?
19. Die Philosophiewerkstatt am 14.Juni ist die letzte Werkstatt vor der Sommerpause. Es wird im Anschluss an die Sitzung ein offener Abend mit voller Restauration angeboten werden und mit der Möglichkeit, über das weitere Vorgehen zu diskutieren (welche Formate, zusätzliche Ereignisse,…).
Einen Überblick über alle Beiträge zur Philosophiewerkstatt nach Themen findet sich HIER
Änerung: 19.März 2015 (Die Künslergruppe Reul & Härtel hat das Foto mit Ihnen durch ein Bild aus ihr Performance (‚visualexploration‘) ersetzen lassen)
Änderung: 20.Nov.2014 (Einfügung Videoschnappschuss von der Uraufführung des Eingangereignisses)
Wie schon zuvor in diesem Blog darauf hingewiesen gab es am 8.November 2014 in der Frankfurt University of Applied Sciences eine recht interessante Veranstaltung INFORMATIK & GESELLSCHAFT. Computer und Geist. Aspekte einer Standortbestimmung. Im Folgenden ein kurzer Bericht mit einigen Schnappschüssen. Alle Bilder sind von Dominik Wolf, dem es gelungen ist, unter schwierigen Lichtverhältnissen doch das eine oder andere Bild zu schiessen. Die beiden ersten Bilder sind allerdings von Anita Henisch, die dann wegen der schwierigen Lichtverhältnisse aufgegeben hatte. Von Dominik Wolf selbst gibt es leider kein Foto, was schade ist, da er die Hauptlast der Organisation getragen hat.
cagentartist im Gespräch mit Guido May vor der Uraufführung von ‚Little CRUNCS symphony No.1‘ Jazz-Schlagzeuger Guido May während der Uraufführung von ‚Little CRUNCS symphony No.1‘
Hier ein Video Schnappschuss von Dominik Wolf. Dies war nicht als Dokumentation geplant; aber da der geplante Tonmitschnitt leider nicht verfügbar ist, ist dies nun das einzige Zeugnis der 20 Minuten-Uraufführung.
Das Stück ‚Little CRUNCS symphony No.1‘ wirkte auf den ersten Blick wie sinfonische Musik, war aber vollständig im Computer generiert worden. Sieben verschiedene Eingangsklänge wurden auf unterschiedliche Weise algorithmisch bearbeitet und miteinander verzahnt. Viele Zuhörer sagten anschliessend, dass für sie das Schlagzeugspiel sehr wichtig gewesen sei. Ohne dieses hätten sie sich mit dem reinen Soundtrack schwer getan. So aber war es ein Erlebnis. Auch für den erfahrenen Jazz-Schlagzeuger Guido May war das Stück, wie er sagte, eine besondere Herausforderung. Alle ihm bekannten Muster passten bei diresdem Stück nicht. Er musster sich die Rolle des Schlagzeugs hier speziell erarbeiten.
13.45 Uhr Begrüßungen
(Moderator Prof. Doeben-Henisch, Sprecher ForschungsCampus FC3 & Informatik Cluster Fb2 Prof. Schäfer, Dekan Fb2 Prof. Morkramer, Vizepräsident Wissenschaft Infrastruktur Forschungstransfer der Frankfurt University of Applied Sciences Prof. Schrader)
Begrüssung und Moderation von Prof.Dr.Gerd Doeben-Henisch
Prof.Doeben-Henisch bei der Begrüßung. Es war die erste Veranstaltung dieser Art für die Informatik an der Hochschule. So war es sehr erfreulich, dass so viele sich aktiv und engagiert bei dieser Veranstaltung beteiligt haben.
Sehr persönliche Grußworte vom Dekan des Fb2 Prof. Achim Morkramer
Prof. Morkramer, der Dekan des Fb2, verstand es, am Beispiel seiner eigenen Familie lebendig werden zu lassen, wie schnell die Computer innerhalb von zwei Generationen aus dem Nichts aufstiegen und heute alles durchdringen. Erst jetzt beginnen wir Menschen scheinbar zu begreifen, welche große Folgen dies für uns alle haben kann, nicht nur positiv, sondern auch negativ.
Grussworte mit einer Vision: Vizepräsident für Infrastruktur, Weiterbildung und Forschung, Prof.Dr. Ulrich Schrader
Der Vizepräsident für Weiterbildung, Infrastruktur und Forschung, Prof. Dr. Schrader, griff sich aus den vielfältigen Entwicklungen jenen Bereich heraus, der ihn selbst besonders betrifft, den Bereich neuer Unterrichtstechnologien. So wunderbar diese neue Welt auch erscheint, er machte darauf aufmerksam, dass der Aufwand für eine volle Nutzung dieser neuen technologischen Möglichkeiten, von einer einzelnen Hochschule kaum gestemmt werden kann. Er wagte einen visionären Ausblick dahingehend, ob nicht Hochschule, Behörden und Wirtschaft zusammen ein ‚Leuchtturmprojekt‘ gemeinsamer neuer digitaler interaktiver Lernräume stemmen sollten. Eine Frage, die noch immer weiterhallt, auch nach der Veranstaltung.
14.00 Uhr Geist zum Nulltarif? Philosophische Aspekte zur Herkunft und zur Zukunft der Informatik. Vortrag und Diskussion
(Prof. Dr. phil. Dipl. theol G. Doeben-Henisch)
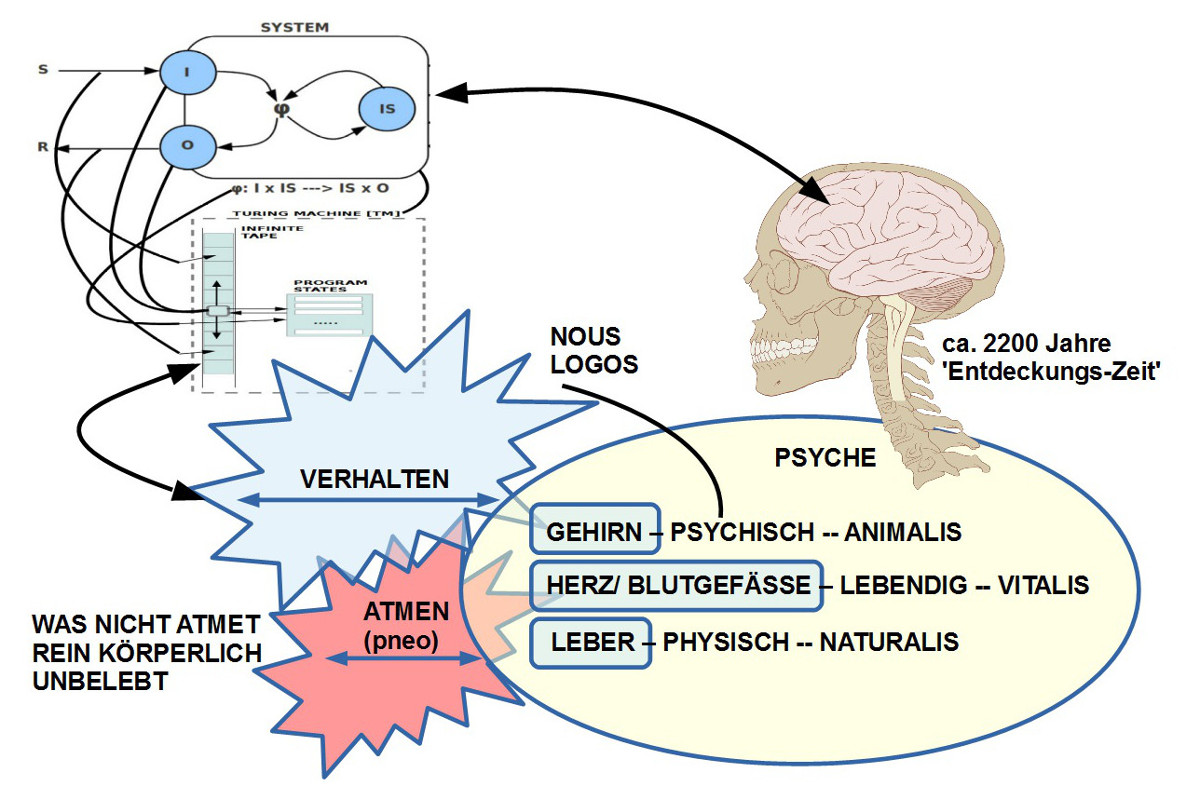
Eine Folie aus dem Vortrag von Prof. Doeben-Henisch
Unter dem Titel ‚Geist zum Nulltarif‘ ordnete Prof. Doeben-Henisch den Menschen mit seiner ‚Geistigkeit‘ ein in die Ideengeschichte (‚Geist‘ in der antiken griechischen Philosophie, hier verankert im Phänomen des ‚Atmens‘ (Verb: ‚pneo‘) erweitert zum Lebensprinzip (Substantiv ‚pneuma‘)) und in die Evolution des Lebendigen (‚Geist‘ als eine inhärente Eigenschaft des Biologischen selbst). Die strukturellen Übereinstimmungen zwischen dem Prinzip Computer und biologischen Zellen bis hin zum Gehirn lassen heute nicht erkennen, warum der Computer den Menschen in seinen Fähigkeiten nicht übertreffen können sollte. Die – besonders in den USA – vertretene Hypothese von der kommenden ‚technologischen Singularität‘ geht schon ganz selbstverständlich davon aus, dass die Tage der Menschen gezählt sind; die ‚intelligenten Maschinen‘ werden ‚übernehmen’…
15.00 Uhr Informatik und Gesellschaft Soziologische und kulturanthropologische Aspekte der neuen Informationstechnologien. Vortrag und Diskussion
(Prof. Dr. habil. Dipl. soz. Manfred Faßler)
Reflexion im Vollzug: Prof.Dr.habil Manfred Fassler (Goethe Universität)
Dass diese ‚Anpassbarkeit‘ des Computers an gesellschaftliche Abläufe und psychischen Bedürfnissen massive Rückwirkungen auf das Verhalten der Menschen und viele soziale Strukturen hat, thematisierte Prof. Fassler. Er identifizierte in den beobachtbaren Veränderungen einen großen Forschungsbedarf: wie können wir verhindern, dass die Menschen zu bloßen ‚Anhängsel‘ eines einzigen großen kybernetischen Systems werden, das einer ’smarten Humanität‘ zuwider läuft? Und in der Tat, der Reflexionsbedarf der heutigen Informatik gerade mit Blick auf Soziologie und Kulturanthropologie ist drängend; wo aber sind die zugehörigen Forschungsgruppen und Forschungsprogramme?
Die wunderbaren Bilder von Härtel/ Reul, die auf der digitalen Verarbeitung von analogen Prozessen in verschiedenen Flüssigkeiten beruhten, ließen in der ersten Pause dann etwas Leichtigkeit aufblitzen, einen Hauch von Schönheit. Zu erwähnen ist, dass Philip Reul auch Absolvent des Bachelor-Studiengangs Informatik der Hochschule ist sowie des interdisziplinären Masterstudiengangs ‚Barrierefreie Systeme‘ (BaSys).
visualexploration-8nov2014 von Härtel & Reul
16.30 Uhr Verkehr von morgen. Total umsorgt, total verkauft? Über Uber, Überwachung, und die neue Mobilität. Vortrag und Diskussion
(Prof. Dr. Jörg Schäfer)
Klar und direkt: Prof.Dr. Jörg Schäfer zur Missachtung der Privatsphäre
Prof. Schäfer demonstrierte dann am Beispiel der Mauterfassung, wie das vorhandene Knowhow der Informatik von der Politik nicht genutzt wird, um die Privatsphäre bei der Mauterfassung zu wahren. Stattdessen wird direkt auf die Privatheit zugegriffen. Am Beispiel des neuen Fahrgastvermittlungssystem Uber illustrierte Schäfer, wie einige wenige Kapitalgeber mit einer einfachen, billigen Software weltweit hohe Vermittlungsgebühren einziehen können, ohne juristische Verantwortung für das Fahrgastgeschäft selbst zu übernehmen. Er fragte, warum die Bürger dies nicht selbst organisieren, z.B. mit einer ‚genossenschaftlichen Bürgerplattform‘. Noch weiter gedacht: warum sollten Studierende, Professoren und Bürger nicht solch eine Genossenschaft gründen?
17.30 Uhr Robot-Fabriken. Erhöhung der Produktivität; wo bleibt die Arbeit? Vortrag und Diskussion
( Prof. Dr. Kai-Oliver Schocke)
Konnte begeistern: Prof.Dr. Oliver Schocke (Fb3) zur Notwendigkeit der Automatisierung
Das Thema ‚Automatisierung‘ bzw. ‚Roboter-Fabriken‘ ist in der Öffentlichkeit wegen unterstelltem Arbeitsplatzverlust schon mit Vorbehalten verhaftet. Prof. Schocke verstand es aber, in einem sehr engagierten Vortrag zunächst einmal die Notwenigkeit einer Produktivitätssteigerung durch weiter automatisierte Fabriken zu klären. Der internationale Konkurrenzdruck zwingt Deutschland, hier an vorderster Stelle mit zu halten. Allerdings zeigte die lebhafte Diskussion, dass damit das Problem der oft zitierten Arbeitsplatzvernichtung möglicherweise noch nicht völlig beantwortet ist. In der Diskussion wurde klar, dass hier alle betroffenen gesellschaftlichen Kräfte herausgefordert sind nach Lösungen zu suchen. den Unternehmen alleine kann man dies nicht anlasten.
Tobias Schmitt nach seiner Performance im Gespräch mit einer Teilnehmerin
Tobias Schmitt, ehemaliger Absolvent der Informatik – noch mit dem klassischen Diplom –, der zugleich seit gut 20 Jahren auch experimentelle Musik produziert, komponiert, performed, zeigte ein eigens Kunstvideo parallel zu einem eigenen Soundtrack, den er live spielte.
19.30 Uhr Video Slam zum Thema Informatik und Gesellschaft (Länge eines Videos maximal 7-Min, künstlerisch oder wissenschaftlich, Publikumspreise für die zwei besten Beiträge)
Video–Slam Preisverleihung: Wie man sieht, herrschte eine gute Stimmung. Von links nach rechts: die Professoren Schäfer und Doeben-Henisch mit den Preisträgern Siegfried Kärcher und Tom Pluemmer
Obgleich die Vorlaufzeit für den Videowettbewerb vergleichsweise sehr kurz war hatte es Einsendungen gegeben und es war möglich, den vom Förderkreis der Hochschule gestifteten Preis an zwei Preisträger zu überreichen. Sowohl Siegfried Härtel wie auch Tom Pluemmer sind profiliert Kunstschaffende. Während Tom Pluemmer seinen Schwerpunkt im Bereich Film hat, hat Siegfried Kärcher in seinem Leben schon eine ganze Bandbreite von künstlerische Aktivitäten aufzuweisen. Darin kommt eine intensive Auseinandersetzung mit Computern in ihren vielschichtigen Einsatzmöglichkeiten ebenso vor wie Lichttechnik, Sounddesign und Videokunst, um nur einiges zu nennen.
Das Cafe1 während der Pausen – Essen, Trinken, Kommunizieren
21.30-23.00 Uhr Ausgangsereignis Computermediated Sound/Images 4
(Werkstattgespräch mit den Künstlern; Digital Jam-Session)
Digitale Jam-Session: Tobias Schmitt und Guido May nach dem Video-Slam
Hier eine Momentaufnahme von der inspirierenden Improvisation Tobias Schmitt & Guido May. Leider viel zu kurz …
Weitere Berichte, Kommentare können möglicherweise noch folgen. Insbesondere sollen noch Links auf die beiden prämierten Videos folgen.
Eine erste Nachreflexion von cagent zur Tagungfindet sich HIER.
Einen Überblick über alle Einträge in diesem Blog nach Titeln findet sich HIER.
Letzte Änderung (mit Erweiterungen): 12.April 2013, 06:26h
ALLGEMEINE EINSCHÄTZUNGEN ZU SEELE, GEIST UND WISSENSCHAFTEN
1. Im nächsten Kapitel ‚Mind‘ (etwa ‚Geist‘ (es gibt keine eindeutigen begrifflichen Zuordnungen in diesem Fall)) (SS.177-196) handelt Kauffman vom ‚Geist‘ des Menschen einschließlich dem besonderen Aspekt ‚(Selbst-)Bewusstsein‘ (‚consciousness‘) mit jenen Beschreibungsversuchen, die er für nicht zutreffend hält. Es folgt dann ein Kapitel ‚The Quantum Brain‘ (etwa ‚Das Quantengehirn‘) (SS.197-229), in dem er seine mögliche Interpretation vorstellt. Seine eigene Grundüberzeugung stellt er gleich an den Anfang, indem er sagt, dass der menschliche Geist (i) nicht ‚algorithmisch‘ sei im Sinne eines berechenbaren Ereignisses, sondern (ii) der Geist sei ‚Bedeutung und tue Organisches‘ (‚is a meaning and doing organic system‘). (iii) Wie der Geist Bedeutung erzeuge und sein Verhalten hervorbringe, das sei jenseits der aktuellen wissenschaftlichen Erklärungsmöglichkeiten.(vgl. S.177)
2. [Anmk: Seiner grundsätzlichen Einschätzung, dass eine vollständige wissenschaftliche Erklärung bislang nicht möglich sei (iii), kann ich nur zustimmen; wir haben mehr Fragen als Antworten. Die andere Aussage (ii), dass Geist ‚is a meaning and doing organic system‘, ist schwierig zu verstehen. Was soll es heißen, dass der Geist (‚mind‘) ‚doing organic system‘? Hier kann man nur raten. Ein sehr radikaler Interpretationsversuch wäre, zu sagen, dass der ‚Geist‘ etwas ist, was die Entstehung von organischen Systemen ermöglicht. Damit würde Geist fast schon zu einem ‚inneren Prinzip der Materie‘. Aus den bisherigen Ausführungen von Kauffmann gäbe es wenig Anhaltspunkte, das zu verstehen. Die andere Aussage (i), dass ‚Geist‘ (‚mind‘) ‚Bedeutung‘ sei, ist ebenfalls nicht so klar. Die Standardinterpretation von ‚Bedeutung‘ wird von der Semiotik geliefert. Innerhalb der Semiotik ist aber speziell der Begriff der Bedeutung, wie man sehr schnell sehen kann keinesfalls einfach oder klar. Ohne eine eigene Theorie verliert man sich in den historisch gewachsenen Verästelungen. Es gibt eine Vielzahl von Denkversuchen, die sich nicht auf einen gemeinsamen Denkrahmen zurückführen lassen. Die Geschichte der Ideen ist generell ein faszinierendes Phänomen ohne eine zwingende Logik. Die muss man sich selbst erarbeiten.]
ALGORITHMISIERUG VON GEIST
3. Auf den Seiten 178-182 zählt er einige wichtige Personen und Konzepte auf, die der Begriff ‚algorithmisch‘ in seiner historischen Entwicklung konnotiert. Da ist einmal Turing, der ein mathematisches Konzept von ‚Berechenbarkeit‘ gefunden hat, das bis heute die Grundlage für alle wichtigen Beweise bildet. Daneben von Neumann, der ’nebenher‘ eine Architektur für reale Computer erfunden hat, die als Von-Neumann-Architektur zum Ausgangspunkt der modernen programmierbaren Computers geworden ist. Ferner stellt er McCulloch vor und Pitts. McCulloch und Pitts gelten als jene, die als erstes eine erfolgreiche Formalisierung biologischer Nervenzellen durchgeführt haben und mit ihren McCulloch-Pitts Neuronen das Gebiet der künstlichen neuronalen Zellen begründeten. Das Besondere am frühen Konzept von McCulloch-Pitts war, dass sie nicht nur ein formales Modell von vernetzten künstlichen Neuronen definierten, sondern dass sie zusätzlich eine Abbildung dieser Neuronen in eine Menge formaler Aussagen in dem Sinne vornahmen, dass ein Neuron nicht nur eine Prozesseinheit war mit dem Zustand ‚1‘ oder ‚0‘, sondern man ein Neuron zugleich auch als eine Aussage interpretieren konnte, die ‚wahr‘ (‚1‘) sein konnte oder ‚falsch‘ (‚0‘). Damit entstand parallel zu den ‚rechnenden‘ Neuronen – in einer ’symbolischen‘ Dimension – eine Menge von interpretierten logischen Aussagen, die man mit logischen Mitteln bearbeiten konnte. Kauffman diskutiert den Zusammenhang zwischen diesen drei Konzepten nicht, stellt dann aber einen Zusammenhang her zwischen dem Formalisierungsansatz von McCulloch-Pitts und seinem eigenen Konzept eines ‚Boolschen Network Modells‘ (‚Boolean network model‘) aus Kapitel 8 her [hatte ich im Detail nicht beschrieben][Anmerkung: Vor einigen Jahren hatte ich mal versucht, die Formalisierungsansätze von McCulloch und Pitts zu rekonstruieren. Sie benutzen die Logik, die damals Carnap entwickelt hatte, erweitert um den Faktor Zeit. Mir ist keine konsistente Rekonstruktion gelungen, was nicht viel besagen muss. Möglicherweise war ich zu dumm, zu verstehen, was Sie genau wollen.]
4. Sowohl am Beispiel des ‚rechnenden Neurons‘ (was Kauffman und viele andere als ’subsymbolisch‘ bezeichnen) wie auch am Beispiel der interpretierten Aussagen (die von Kauffman als ’symbolisch‘ bezeichnete Variante) illustriert Kauffman, wie diese Modelle dazu benutzt werden können, um sie zusätzlich in einer dritten Version zu interpretieren, nämlich als ein Prozessmodell, das nicht nur ‚Energie‘ (‚1‘, ‚0‘) bzw. ‚wahr’/ ‚falsch‘ verarbeitet, sondern diese Zustände lassen sich abbilden auf ‚Eigenschaften des Bewusstseins‘, auf spezielle ‚Erlebnisse‘, die sich sowohl als ‚elementar’/ ‚atomar‘ interpretieren lassen wie auch als ‚komplex’/ ‚abstrahiert‘ auf der Basis elementarer Erlebnisse. (vgl. S.180f)
5. [Anmerkung: Diese von Kauffman eingeführten theoretischen Konzepte tangieren sehr viele methodische Probleme, von denen er kein einziges erwähnt. So muss man sehr klar unterscheiden zwischen dem mathematischen Konzept der Berechenbarkeit von Turing und dem Architekturkonzept von von Neumann. Während Turing ein allgemeines mathematisches (und letztlich sogar philosophisches!) Konzept von ‚endlich entscheidbaren Prozessen‘ vorstellt, das unabhängig ist von irgend einer konkreten Maschine, beschreibt von Neumann ein konkrete Architektur für eine ganze Klasse von konkreten Maschinen. Dass die Nachwelt Turings mathematisches Konzept ‚Turing Maschine‘ genannt hat erweckt den Eindruck, als ob die ‚Turing Maschine‘ eine ‚Maschine sei. Das aber ist sie gerade nicht. Das mathematische Konzept ‚Turing Maschine‘ enthält Elemente (wie z.B. ein beidseitig unendliches Band), was niemals eine konkrete Maschine sein kann. Demgegenüber ist die Von-Neumann-Architektur zu konkret, um als Konzept für die allgemeine Berechenbarkeit dienen zu können. Ferner, während ein Computer mit einer Von-Neumann-Architektur per Definition kein neuronales Netz ist, kann man aber ein neuronales Netz auf einem Von-Neumann-Computer simulieren. Außerdem kann man mit Hilfe des Turing-Maschinen Konzeptes untersuchen und feststellen, ob ein neuronales Netz effektiv entscheidbare Berechnungen durchführen kann oder nicht. Schließlich, was die unterschiedlichen ‚Interpretationen‘ von neuronalen Netzen angeht, sollte man sich klar machen, dass ein künstliches neuronales Netz zunächst mal eine formale Struktur KNN=[N,V,dyn] ist mit Mengen von Elementen N, die man Neuronen nennt, eine Menge von Verbindungen V zwischen diesen Elementen, und einer Übergangsfunktion dyn, die sagt, wie man von einem aktuellen Zustand des Netzes zum nächsten kommt. Diese Menge von Elementen ist als solche völlig ’neutral‘. Mit Hilfe von zusätzlichen ‚Abbildungen‘ (‚Interpretationen‘) kann man diesen Elementen und ihren Verbindungen und Veränderungen nun beliebige andere Werte zuweisen (Energie, Wahr/Falsch, Erlebnisse, usw.). Ob solche Interpretationen ’sinnvoll‘ sind, hängt vom jeweiligen Anwendungskontext ab. Wenn Kauffman solche möglichen Interpretationen aufzählt (ohne auf die methodischen Probleme hinzuweisen), dann sagt dies zunächst mal gar nichts.]
GEHIRN ALS PHYSIKALISCHER PROZESS
6. Es folgt dann ein kurzer Abschnitt (SS.182-184) in dem er einige Resultate der modernen Gehirnforschung zitiert und feststellt, dass nicht wenige Gehirnforscher dahin tendieren, das Gehirn als einen Prozess im Sinne der klassischen Physik zu sehen: Bestimmte neuronale Muster stehen entweder für Vorgänge in der Außenwelt oder stehen in Beziehung zu bewussten Erlebnissen. Das Bewusstsein hat in diesem Modell keinen ‚kausalen‘ Einfluss auf diese Maschinerie, wohl aber umgekehrt (z.B. ‚freier Wille‘ als Einbildung, nicht real).
7. [Anmk: Das Aufzählen dieser Positionen ohne kritische methodische Reflexion ihrer methodischen Voraussetzungen und Probleme erscheint mir wenig hilfreich. Die meisten Aussagen von Neurowissenschaftlern, die über die Beschreibung von neuronalen Prozessen im engeren Sinne hinausgehen sind – vorsichtig ausgedrückt – mindestens problematisch, bei näherer Betrachtung in der Regel unhaltbar. Eine tiefergreifende Diskussion mit Neurowissenschaftlern ist nach meiner Erfahrung allerdings in der Regel schwierig, da ihnen die methodischen Probleme fremd sind; es scheint hier ein starkes Reflexions- und Theoriedefizit zu geben. Dass Kauffman hier nicht konkreter auf eine kritische Lesart einsteigt, liegt möglicherweise auch daran, dass er in den späteren Abschnitten einen quantenphysikalischen Standpunkt einführt, der diese schlichten klassischen Modellvorstellungen von spezifischen Voraussetzungen überflüssig zu machen scheint.]
KOGNITIONSWISSENSCHAFTEN; GRENZEN DES ALGORITHMISCHEN
8. Es folgt dann ein Abschnitt (SS.184-191) über die kognitiven Wissenschaften (‚cognitive science‘). Er betrachtet jene Phase und jene Strömungen der kognitiven Wissenschaften, die mit der Modellvorstellung gearbeitet haben, dass man den menschlichen Geist wie einen Computer verstehen kann, der die unterschiedlichsten Probleme ‚algorithmisch‘, d.h. durch Abarbeitung eines bestimmten ‚Programms‘, löst. Dem stellt Kauffman nochmals die Unentscheidbarkeits- und Unvollständigkeitsergebnisse von Gödel gegenüber, die aufzeigen, dass alle interessanten Gebiete der Mathematik eben nicht algorithmisch entscheidbar sind. Anhand der beiden berühmten Mathematiker Riemann und Euler illustriert er, wie deren wichtigsten Neuerungen sich nicht aus dem bis dahin Bekanntem algorithmisch ableiten ließen, sondern auf ‚kreative Weise‘ etwas Neues gefunden haben. Er zitiert dann auch die Forschungen von Douglas Medin, der bei seinen Untersuchungen zur ‚Kategorienbildung‘ im menschlichen Denken auf sehr viele ungelöste Fragen gestoßen ist. Wahrscheinlichkeitstheoretische Ansätze zur Bildung von Clustern leiden an dem Problem, dass sie nicht beantworten können, was letztlich das Gruppierungskriterium (‚Ähnlichkeit‘, welche?) ist. Aufgrund dieser grundsätzlichen Schwierigkeit, ‚Neues‘, ‚Innovatives‘ vorweg zu spezifizieren, sieht Kauffman ein grundsätzliches Problem darin, den menschlichen Geist ausschließlich algorithmisch zu definieren, da Algorithmen – nach seiner Auffassung – klare Rahmenbedingungen voraussetzen. Aufgrund der zuvor geschilderten Schwierigkeiten, solche zu bestimmten, sieht er diese nicht gegeben und folgert daraus, dass die Annahme eines ‚algorithmischen Geistes‘ unzulänglich ist.
9. [Anmk: Die Argumente am Beispiel von Goedel, Riemann, Euler, und Medin – er erwähnte auch noch Wittgenstein mit den Sprachspielen – würde ich auch benutzen. Die Frage ist aber, ob die Argumente tatsächlich ausreichen, um einen ‚algorithmischen Geist‘ völlig auszuschliessen. Zunächst einmal muss man sich klar machen, dass es ja bislang überhaupt keine ‚Theorie des Geistes an sich‘ gibt, da ein Begriff wie ‚Geist‘ zwar seit mehr als 2500 Jahren — betrachtet man nur mal den europäischen Kulturkreis; es gibt ja noch viel mehr! — benutzt wird, aber eben bis heute außer einer Unzahl von unterschiedlichen Verwendungskontexten keine einheitlich akzeptierte Bedeutung hervorgebracht hat. Dies hat u.a. damit zu tun, dass ‚Geist‘ ja nicht als ‚direktes Objekt‘ vorkommt sondern nur vermittelt in den ‚Handlungen‘ und den ‚Erlebnissen‘ der Menschen in unzähligen Situationen. Was ‚wirklich‘ mit ‚Geist‘ gemeint ist weiß insofern niemand, und falls doch, würde es allen anderen nichts nützen. Es gibt also immer nur partielle ‚Deutungsprojekte‘ von denen die kognitive Psychologie mit dem Paradigma vom ‚Geist‘ als ‚Computerprogramm‘ eines unter vielen ist. Hier müsste man dann nochmals klar unterscheiden, ob die psychologischen Modelle explizit einen Zusammenhang mit einer zugrunde liegenden neuronalen Maschinerie herstellen oder nicht. Versteht man die wissenschaftliche Psychologie als ein ‚empirisches‘ Deutungsprojekt, dann muss man annehmen, dass sie solch einen Zusammenhang explizit annimmt. Damit wäre ein algorithmisches Verhalten aus der zugrunde liegenden neuronalen Maschinerie herzuleiten. Da man nachweisen kann, dass ein neuronales Netz mindestens so rechenstark wie eine Turingmaschine ist, folgt daraus, dass ein neuronales Netzwerk nicht in allen Fällen algorithmisch entscheidbar ist (Turing, 1936, Halteproblem). Dies bedeutet, dass selbst dann, wenn der menschliche Geist ‚algorithmisch‘ wäre, daraus nicht folgt, dass er alles und jedes berechnen könnte. Andererseits, wie wir später sehen werden, muss man die Frage des Gehirns und des ‚Geistes‘ vermutlich sowieso in einem ganz anderen Rahmen bedenken als dies in den Neurowissenschaften und den Kognitionswissenschaften bislang getan wird.]
GEIST OPERIERT MIT ‚BEDEUTUNG‘
10. Es folgen (SS.192-196) Überlegungen zur Tatsache, dass der ‚Geist‘ (‚mind‘) mit ‚Bedeutung‘ (‚meaning‘) arbeitet. Welche Zeichen und formale Strukturen wir auch immer benutzen, wir benutzen sie normalerweise nicht einfach ’nur als Zeichenmaterial‘, nicht nur rein ’syntaktisch‘, sondern in der Regel im Kontext ‚mit Bezug auf etwas anderes‘, das dann die ‚Bedeutung‘ für das benutzte Zeichenmaterial ausmacht. Kauffman bemerkt ausdrücklich, dass Shannon in seiner Informationstheorie explizit den Aspekt der Bedeutung ausgeschlossen hatte. Er betrachtete nur statistische Eigenschaften des Zeichenmaterials. Ob ein Zeichenereignis eine Bedeutung hat bzw. welche, das muss der jeweilige ‚Empfänger‘ klären. Damit aber Zeichenmaterial mit einer möglichen Bedeutung ‚verknüpft‘ werden kann, bedarf es eines ‚Mechanismus‘, der beides zusammenbringt. Für Kauffman ist dies die Eigenschaft der ‚Agentenschaft‘ (‚agency‘). Wie der menschliche Geist letztlich beständig solche neuen Bedeutungen erschafft, ist nach Kauffman bislang unklar.
11. Es folgen noch zwei Seiten Überlegungen zur Schwierigkeit, die nichtlineare Relativitätstheorie und die lineare Quantentheorie in einer einzigen Theorie zu vereinen. Es ist aber nicht ganz klar, in welchem Zusammenhang diese Überlegungen zur vorausgehenden Diskussion zum Phänomen der Bedeutung stehen.
Der universale Weltprozess, der Geist, und das Experiment
Zur Erinnerung, Auslöser für die Idee mit dem Experiment war das Nachtgespräch im INM……
Am 15.Dez012 11:00h gab es ein denkwürdiges Treffen im Café Siesmayer (Frankfurt, neben dem Palmgarten). Für mich war es das erste Mal dort; ein angenehmer Ort, um zu reden (und natürlich auch, um Kaffee zu trinken).
Die ‚Besetzung‘ ist kurz beschrieben: einer mit Schwerpunkt Soziologie, einer mit Schwerpunkt Physik, einer mit Schwerpunkt Informatik, Psychologie und Erkenntnistheorie.
Nachdem die Gedanken mehrere Kreise, Ellipsen, Achten und diverse Verschlingungen gezogen hatten näherten wir uns dem zentralen Knackpunkt: wie lokalisieren wir den ‚Geist‘ und worin soll das ‚Experiment‘ bestehen?
Der Referenzpunkt der Überlegungen wurde gebildet von der Annahme, dass wir zu Beginn des Universums einen Übergang von ‚Energie‘ zu ‚Materie‘ haben, nicht als das ‚ganz Andere‘, sondern als eine andere ‚Zustandsform‘ von Energie.
Und dann beobachten wir einen weiteren Übergang von Energie in materielle Strukturen‘, nämlich dort, wo die Energie als sogenannte ‚freie Energie‘ den Übergang von einfachen chemischen Verbindungen zu immer komplexeren chemischen Verbindungen begünstigt, zu Zellen, zu mehrzelligen Systemen, bis hin zu den Pflanzen, Tieren und dem homo sapiens sapiens, einer Lebensform, zu der wir ‚als Menschen‘ gehören.
Und es sieht so aus, als ob diese komplexen biologischen Strukturen eine fast ‚triebhafte‘ Tendenz besitzen, die biologische motivierte Strukturbildung beständig zu bestärken, zu beschleunigen, zu intensivieren.
Die beobachtbare Strukturbildung folgt allerdings bestimmten ‚Vorgaben‘: Im Falle biologischer Systeme stammen diese Vorgaben aus den Nervensystemen bzw. genauer den Gehirnen. Allerdings, und dies ist der entscheidende Punkt, es sind nicht die physikalisch-chemischen Eigenschaften der Gehirne als solche, die die Vorgaben ‚kodieren‘, sondern es ist ein Netzwerk von ‚Informationen‘ bzw. ‚Bedeutungen‘ , die zwar mit Hilfe der der physikalisch-chemischen Eigenschaften realisiert werden, die aber nicht aus diesen direkt abgeleitet werden können!!!!!! Die informatorisch-semantische Dimension biologischer Systeme ermöglicht all das, was wir als ‚intelligent‘ bezeichnen bzw. all das, was wir als ‚Ausdruck des Geistes‘ notieren. Für diese informatorisch-semantische (= geistige!?) Dimension gibt es aber — bisher! — keine Begründung in der bekannten physikalischen Welt.
Hat man diesen Faden erst einmal aufgenommen, dann kann man den Weg der Entwicklung weiter zurück gehen und wird feststellen, dass es diese geheimnisvolle informatorisch-semantische Dimension auch schon auf der Ebene der Zelle selbst gibt. Denn die ‚Steuerung‘ der Proteinbildung bis hin zur Ausformung kompletter Phänotypen erfolgt über ein Molekül (DNA (auch RNA und andere)), das als solches zwar komplett über seine physikalischen Eigenschaften beschrieben werden kann, dessen ’steuernde Wirkung‘ aber nicht direkt von diesen physikalischen Eigenschaften abhängt, sondern (wie Paul Davies ganz klar konstatiert), von etwas, was wir ‚Information‘ nennen bzw. was ich als ‚Bedeutung‘ bezeichnen würde, eben jene (semantische) Beziehung zwischen einem Materiekomplex auf der einen Seite und irgendwelchen anderen Materiekomplexen auf der anderen Seite. Und diese semantischen Beziehungen sind ’spezifisch‘. Wo kommen diese her? Die physikalischen Eigenschaften selbst liefern dafür keinerlei Ansatzpunkte!!!!
Interessant ist auf jeden Fall, dass die zentrale Rolle der semantischen Dimension im Bereich entwickelter Nervensysteme sich schon bei der ersten Zelle findet, und zwar an der zentralen Stelle, an der bislang die Wissenschaft das Spezifikum des Biologischen verortet. Strukturell ist die semantische Dimension in beiden Fällen völlig identisch und in beiden Fällen physikalisch bislang unerklärlich.
Nach allem, was wir bis heute wissen, ist das, was wir mit ‚Geist‘ meinen, genau in dieser semantischen Dimension zu verorten. Dies aber bedeutet, der Geist ‚erscheint‘ nicht erst nach ca. 13 Milliarden Jahren nach dem Big Bang, sondern mindestens mit dem Entstehen der ersten Zellen, also vor ca. 3.8 Mrd Jahren.
Betrachtet man die ’semantische Dimension‘ aus einem gewissen ‚gedanklichen Abstand‘, dann kann man auch formulieren, dass das ‚Wesen des Semantischen‘ darin besteht, dass eine Materiestruktur das Verhalten anderer Materiestrukturen ’steuert‘. In gewisser Weise gilt dies letztlich auch für die Wechselwirkungen zwischen Atomen. Fragt sich, wie man die Beziehung zwischen Energie ‚als Energie‘ und Energie ‚als Materie‘ betrachten kann/ muss. Die Ausbildung von immer mehr ‚Differenzen‘ bei der Abkühlung von Energie ist jedenfalls nicht umkehrbar, sondern ‚erzwungen‘, d.h. Energie als Energie induziert Strukturen. Diese Strukturen wiederum sind nicht beliebig sondern induzieren weitere Strukturen, diese wiederum Strukturen bei denen immer mehr ‚zutage‘ tritt, dass die Strukturbildung durch eine semantische Dimension gesteuert wird. Muss man annehmen, dass die ’semantische Struktur‘, die auf diesen verschiedenen Niveaus der Strukturbildung sichtbar wird, letztlich eine fundamentale Eigenschaft der Materie ist? Dies würde implizieren (was ja auch schon nur bei Betrachtung der materiellen Strukturen deutlich wird), dass Energie ‚als Energie‘ nicht neutral ist, sondern eine Form von Beziehungen repräsentiert, die im Heraustreten der Strukturen sichtbar werden.
Sollten alle diese Überlegungen treffen, dann kann man mindestens zwei Hypothesen formulieren: (i) das, was wir mit ‚Geist‘ benennen, das ist kein ’spätes‘ Produkt der Evolution, sondern von allem Anfang das innere treibende Prinzip aller Strukturbildungen im Universum; (ii) das, was wir mit ‚Geist‘ benennen, ist nicht gebunden an die biologischen Körper, sondern benötigt als Vorgabe nur etwas, das die notwendigen ‚Unterschiede‘ repräsentiert.
Der heute bekannte ‚digital elektronisch realisierte Computer‘ ist ein Beispiel, wie man semantische Dimensionen ohne Benutzung biologischer Zellen realisieren kann. Wie viel der bekannten menschlichen Intelligenz (und damit des unterstellten ‚Geistes‘) mit dieser Technologie ’simulierbar‘ ist, ist umstritten. Die Experten der Berechenbarkeit — und dazu zählt auf jeden Fall auch Turing, einer der Väter der modernen Theorie der Berechenbarkeit — vermuten, dass es keine Eigenschaft der bekannten Intelligenz gibt, die sich nicht auch mit einer ‚technologisch basierten‘ Struktur realisieren lässt. Die Schwierigkeiten bei nichtbiologisch basierten Intelligenzen im Vergleich zu biologisch basierten Intelligenzen liegen ‚einzig‘ dort, wo die Besonderheiten des Körpers in die Bereitstellung von Ereignissen und deren spezifische Verknüpfungen eingehen (was direkt nachvollziehbar ist). Diese spezifische Schwierigkeit stellt aber nicht die Arbeitshypothese als solche in Frage.
Die ‚Besonderheiten des biologischen Körpers‘ resultieren aus spezifischen Problemen wie Energiebeschaffung und Energieverarbeitung, Bewegungsapparat, Anpassung an Umgebungsbedingungen, Fortpflanzung, Wachstumsprozesse, der Notwendigkeit des Individuellen Lernens, um einige der Faktoren zu nennen; diese körperlichen Besonderheiten gehen der semantischen Dimension voraus bzw. liegen dieser zugrunde. Die technisch ermöglichte Realisierung von ‚Intelligenz‘ als beobachtbarer Auswirkung der nicht beobachtbaren semantischen Dimension ist als nicht-biologische Intelligenz auf diese Besonderheiten nicht angewiesen. Sofern die nicht-biologische Intelligenz aber mit der biologischen Intelligenz ‚auf menschenähnliche Weise‘ interagieren und kommunizieren soll, muss sie von diesen Besonderheiten ‚wissen‘ und deren Zusammenspiel verstehen.
Das oft zu beobachtende ’sich lächerlich machen‘ über offensichtliche Unzulänglichkeiten heutiger nicht-biologischer Intelligenzen ist zwar als eine Art ‚psychologischer Abwehrreflex‘ verständlich, aber letztlich irreführend und tatsächlich ‚verblendend‘: diese Reaktion verhindert die Einsicht in einen grundlegenden Sachverhalt, der uns wesentliche Dinge über uns selbst sagen könnte.
Zurück zum Gespräch: aus den oben formulierten Hypothesen (i) und (ii) kann man unter anderem folgendes Experiment ableiten: (iii) Wenn (i) und (ii) stimmen, dann ist es möglich, durch Bereitstellung von geeigneten nicht-biologischen Strukturelementen ‚Geist‘ in Form einer ’semantischen Dimension‘ (! nicht zu verwechseln mit sogenannten ’semantischen Netzen‘!) als ’nicht-biologische Form von ‚Geist‘ ’sichtbar und damit ‚lebbar‘ zu machen. Dies soll durch Installierung einer offenen Arbeitsgruppe am INM Frankfurt in Angriff genommen werden. Offizieller Start 2014. Wir brauchen noch einen griffigen Titel.
Anmerkung: ich habe den Eindruck, dass die Verschiebung der Begrifflichkeit (‚Information‘ bei Paul Davies, ’semantische Dimension‘ von mir) letztlich vielleicht sogar noch weiter geführt werden müsste bis zu ’semiotische Dimension‘. Dann hätten wir den Anschluss an eine sehr große Tradition. Zwar haben nur wenige Semiotiker in diesen globalen und universellen Dimensionen gedacht, aber einige schon (z.B. Peirce, Sebeok). Außerdem ist die ‚Semantik‘ von jeher eine Dimension der Semiotik. Den Ausdruck ‚Semiotische Maschine‘ für das ganze Universum hatte ich ja auch schon in früheren Blogeinträgen benutzt (siehe z.B.: http://cognitiveagent.org/2010/10/03/die-universelle-semiotische-maschine/). Allerdings war mir da der Sachverhalt in manchen Punkten einfach noch nicht so klar.
Natürlich geht dies alles weiter. In gewisser Weise fängt es gerade erst an. Ich habe den Eindruck, dass wir in einer Zeitspanne leben, in der gerade der nächste große Evolutionssprung stattfindet. Jeder kann es spüren, aber keiner weiß genau, wie das ausgeht. Klar ist nur, dass wir uns von den Bildern der letzten Jahrtausende verabschieden müssen. Die Worte und Bilder aller großen Religionen müssen ‚von innen heraus‘ dramatisch erneuert werden. Es geht nicht um ‚weniger‘ Religion, sondern um ‚mehr‘. Thora, Bibel und Koran müssen vermutlich neu geschrieben werden. Was kein grundsätzliches Problem sein sollte da wir als Menschen dem, was/wen wir ‚Gott‘ nennen, nicht vorschreiben können, was und wie er etwas mitteilen möchte. Die ‚Wahrheit‘ geht immer jeglichem Denken voraus, ohne diesen Zusammenhang verlöre jegliches Denken seinen ‚Halt‘ und damit sich selbst. Und weil dies so ist, kann man einen alten Ausspruch ruhig weiter zitieren. „Die Wahrheit wird euch frei machen.“
Eine Übersicht über alle bisherigen Blogeinträgen nach Themen findet sich HIER
[ANMERKUNG: Obwohl Duve den Begriff der Information im Text immer wieder verwendet, wird der Begriff bislang nicht definiert. Selbst an der Stelle, an der er vom Ende der chemischen Evolution spricht, die dann mit Hilfe von DNA/ RNA in die informationsgeleitete Entwicklung übergeht, findet man keine weitere Erklärung. Der einzige greifbare Anhaltspunkt ist der Bezug zur DNA/ RNA, wobei offen bleibt, warum die DNA der RNA vorgeschaltet wurde.]
Duve beschreibt den Kernsachverhalt so, dass wir ein Abhängigkeitsverhältnis haben von der DNA (die zur Replikation fähig ist) über eine Transkription zur RNA (die in speziellen Fällen, Viren, auch zur Replikation fähig ist) mittels Translation (Übersetzung) zu den Proteinen (vgl. S.55f) ; von den Proteinen gäbe es keinen Weg zurück zur RNA (vgl. S.56f). Die RNA hat dabei auch eine enzymatisch-katalytische Rolle.
[ANMERKUNG: Für einen Interpretationsversuch zur möglichen Bedeutung des Begriffs ‚Information‘ in diesem Kontext bietet sich vor allem der Sachverhalt an, dass die ‚Konstruktion‘ eines DNA-Moleküls bzgl. der Anordnung der einzelnen Aminosäurebausteinen nicht deterministisch festgelegt ist. Ist erst einmal ein DNA-Molekül ‚zustande gekommen‘, dann kann es innerhalb des Replikationsmechanismus (kopieren, mischen und mutieren) so verändert werden, dass es nach der Replikation ‚anders‘ aussieht. Diese nicht-deterministischen Veränderungsprozesse sind völlig unabhängig von ihrer möglichen ‚Bedeutung‘! Es ist etwa so, wie ein kleines Kind, das mit einem Haufen von Buchstaben spielen würde, allerdings mit der kleinen Vorgabe, dass es eine fertige ‚Kette‘ von Buchstaben bekommen würde, die es zerschneiden darf, neu zusammenfügen, und gelegentlich einzelne Stellen austauschen darf.
Die Übersetzung dieser DNA-Ketten in Proteine erfolgt dann über den RNA-gesteuerten Mechanismus. Diese Übersetzung folgt ‚in sich‘ festen Regeln, ist von daher im Prinzip deterministisch. Dies bedeutet, dass ohne die DNA-Ketten zwar deterministische Prozesse möglich sind, allerdings ohne die ‚freie Kombinierbarkeit‘ wie im Falle der DNA-Ketten (was aber, siehe Viren, im Prinzp auch gehen könnte). Die standardmäßige Trennung von Replikation und Translation deutet indirekt daraufhin, dass mit dieser Trennung irgendwelche ‚Vorteile‘ einher zugehen scheinen.
Der Clou scheint also darin zu liegen, dass durch die Entkopplung von chemisch fixierten (deterministischen) Übersetzungsmechanismen von den freien erinnerungs- und zufallsgesteuerten Generierungen von DNA-Ketten überhaupt erst die Voraussetzung geschaffen wurde, dass sich das ‚Zeichenmaterial‘ von dem ‚Bedeutungsmaterial‘ trennen konnte. Damit wiederum wurde überhaupt erst die Voraussetzung für die Entstehung von ‚Zeichen‘ im semiotischen Sinne geschaffen (zu ‚Zeichen‘ und ’semiotisch‘ siehe Noeth (2000)). Denn nur dann, wenn die Zuordnung zwischen dem ‚Zeichenmaterial‘ und dem möglichen ‚Bedeutungsmaterial‘ nicht fixiert ist, kann man von einem Zeichen im semiotischen Sinne sprechen. Wir haben es also hier mit der Geburt des Zeichens zu tun (und damit, wenn man dies unbedingt will, von den ersten unübersehbaren Anzeichen von Geist!!!).
Die Rede von der Information ist in diesem Kontext daher mindestens missverständlich, wenn nicht gar schlichtweg falsch. Bislang gibt es überhaupt keine allgemeine Definition von Information. Der Shannonsche Informationsbegriff (siehe Shannon und Weaver (1948)) bezieht sich ausschließlich auf Verteilungseigenschaften von Elementen einer endlichen Menge von Elementen, die als Zeichenmaterial (Alphabet) in einem technischen Übermittlungsprozeß benutzt werden, völlig unabhängig von ihrer möglichen Bedeutung. Mit Zeichen im semiotischen Sinne haben diese Alphabetelemente nichts zu tun. Daher kann Shannon in seiner Theorie sagen, dass ein Element umso ‚wichtiger‘ ist, je seltener es ist. Hier von ‚Information‘ zu sprechen ist technisch möglich, wenn man weiß, was man definiert; diese Art von Information hat aber mit der ‚Bedeutung‘ von Zeichen bzw. der ‚Bedeutung‘ im Kontext von DNA-Ketten nichts zu tun. Die Shannonsche Information gab und gibt es auch unabhängig von der Konstellation DNA – RNA – Proteine.
Auch der Informationsbegriff von Chaitin (1987, 2001) bezieht sich ausschließlich auf Verteilungseigenschaften von Zeichenketten. Je weniger ‚Zufall‘ bei der Bildung solcher Ketten eine Rolle spielt, also je mehr ‚regelhafte Wiederholungen (Muster, Pattern)‘ auftreten, um so eher kann man diese Ketten komprimieren. Benutzt man dann dazu das Shannonsche Konzept, dass der ‚Informationsgehalt‘ (wohlgemerkt ‚Gehalt‘ hier nicht im Sinne von ‚Bedeutung‘ sondern im Sinne von ‚Seltenheit‘!) umso größer sei, je ’seltener‘ ein Element auftritt, dann nimmt der Informationsgehalt von Zeichenketten mit der Zunahme von Wiederholungen ab. Insofern Zeichenketten bei Chaitin Algorithmen repräsentieren können, also mögliche Anweisungen für eine rechnende Maschine, dann hätten nach dieser Terminologie jene Algorithmen den höchsten ‚Informationsgehalt (im Sinne von Shannon)‘, die die wenigsten ‚Wiederholungen‘ aufwiesen; das wären genau jene, die durch eine ‚zufällige Bildung‘ zustande kommen.
Lassen wir den weiteren Aspekt mit der Verarbeitung durch eine rechnende Maschine hier momentan mal außer Betracht (sollte wir später aber noch weiter diskutieren), dann hätten DNA-Ketten aufgrund ihrer zufälligen Bildung von ihrer Entstehung her einen maximale Informationsgehalt (was die Verteilung betrifft).
Die Aussage, dass mit der DNA-RNA die ‚Information‘ in das Geschehen eingreift, ist also eher nichtssagend bzw. falsch. Dennoch machen die speziellen Informationsbegriffe von Shannon und Chaitin etwas deutlich, was die Ungeheuerlichkeit an der ‚Geburt des Zeichens‘ verstärkt: die zufallsgesteuerte Konstruktion von DNA-Ketten verleiht ihnen nicht nur eine minimale Redundanz (Shannon, Chaitin) sondern lässt die Frage aufkommen, wie es möglich ist, dass ‚zufällige‘ DNA-Ketten über ihre RNA-Interpretation, die in sich ‚fixiert‘ ist, Protein-Strukturen beschreiben können, die in der vorausgesetzten Welt lebensfähig sind? Zwar gibt es im Kontext der biologischen (= zeichengesteuerten) Evolution noch das Moment der ‚Selektion‘ durch die Umwelt, aber interessant ist ja, wie es durch einen rein ‚zufallsgesteuerten‘ DNA-Bildungsprozess zu Ketten kommen kann, die sich dann ‚positiv‘ selektieren lassen. Dieses Paradox wird umso stärker, je komplexer die Proteinstrukturen sind, die auf diese Weise erzeugt werden. Die ‚Geordnetheit‘ schon einer einzigen Zelle ist so immens groß, dass eine Beschreibung dieser Geordnetheit durch einen ‚zufälligen‘ Prozess absurd erscheint. Offensichtlich gibt es hier noch einen weiteren Faktor, der bislang nicht klar identifiziert wurde (und der muss im Generierungsprozess von DNA-Ketten stecken).]
[ANMERKUNG: Eine erste Antwort steckt vielleicht in den spekulativen Überlegungen von Duve, wenn er die Arbeiten von Spiegelmann (1967), Orgel (1979) und Eigen (1981) diskutiert (vgl. S.57-62). Diese Arbeiten deuten daraufhin, dass RNA-Molküle Replizieren können und Ansätze zu evolutionären Prozessen aufweisen. Andererseits sind RNA-Moleküle durch Übersetzungsprozesse an Proteinstrukturen gekoppelt. Wenn also beispielsweise die RNA-Moleküle vor den DNA-Ketten auftraten, dann gab es schon RNA-Ketten, die sich in ihrer jeweiligen Umgebung ‚bewährt‘ hatten. Wenn nun — auf eine Weise, die Duve nicht beschreibt — zusätzlich zu den RNA-Ketten DNA-Ketten entstanden sind, die primär nur zur Replikation da waren und die RNA-Ketten dann ’nur‘ noch für die Übersetzung in Proteinstrukturen ‚zuständig‘ waren, dann haben die DNA-Ketten nicht bei ‚Null‘ begonnen sondern repräsentierten potentielle Proteinstrukturen, die sich schon ‚bewährt‘ hatten. Der Replikationsmechanismus stellte damit eine lokale Strategie dar, wie die im realen Raum vorhandenen DNA/ RNA-Ketten den ‚unbekannten Raum‘ möglicher weiterer Proteinstrukturen dadurch ‚absuchen‘ konnten, dass neue ‚Suchanfragen‘ in Form neuer DNA-Moleküle gebildet wurden. Der ‚Akteur‘ war in diesem Fall die komplette Umgebung (Teil der Erde), die mit ihren physikalisch-chemischen Eigenschaften diese Replikationsprozesse ‚induzierte‘. Die einzige Voraussetzung für einen möglichen Erfolg dieser Strategie bestand darin, dass die ‚Sprache der DNA‘ ‚ausdrucksstark‘ genug war, alle für das ‚hochorganisierte Leben‘ notwendigen ‚Ausdrücke‘ ‚bilden‘ zu können. Betrachtet man den RNA-Proteinkonstruktionsprozess als die ‚Maschine‘ und die DNA-Ketten als die ‚Anweisungen‘, dann muss es zwischen der RNA-Proteinmaschine‘ und den DNA-Anweisungen eine hinreichende Entsprechung geben.]
[ANMERKUNG: Die Überlegungen von Duve haben einen weiteren kritischen Punkt erreicht. Um die Optimierung des Zusammenspiels zwischen RNA und Proteinen und ihren Vorformen erklären zu können, benötigt er einen Rückkopplungsmechanismus, der ein schon vorhandenes ‚Zusammenspiel‘ von allen beteiligten Komponenten in einer gemeinsamen übergeordneten Einheit voraussetzt. Diese hypothetische übergeordnete gemeinsame Einheit nennt er ‚Protozelle‘ (‚protocell‘). (vgl.S.65f)]
Die Protein-Erzeugungsmaschinerie (‚proteine-synthesizing machinery‘) besteht aus mehreren Komponenten. (i) Das Ribosom heftet eine Aminosäure an eine wachsende Peptid-Kette, quasi ‚blindlings‘ entsprechend den determinierenden chemischen Eigenschaften. (vgl. S.66) Das Bindeglied zwischen den ‚informierenden‘ Aminosäuren und den zu bildenden Petidketten (Proteinen) bildet die ‚Boten-RNA‘ (‚messenger RNA, mRNA‘), in der jeweils 3 Aminosäuren (Aminosäuren-Triplets) als ‚Kodon‘, also 4^3=64, eine von 64 möglichen Zieleinheiten kodieren. Dem Kodon entspricht in einer ‚Transport-RNA‘ (‚transfer-RNA, tRNA‘) dann ein ‚Antikodon‘ (ein chemisch komplementäres Aminosäure-Triplet), an das genau eine von den 22 (21) biogenen Aminosäuren ‚angehängt‘ ist. Durch diesen deterministischen Zuordnungsprozess von mRNA-Kodon zu tRNA-Antikodon und dann Aminosäure kann eine Peptidkette (Protein) Schritt für Schritt entstehen. Diejenigen Zieleinheiten aus den 64 Möglichen, die nicht in eine Aminosäure übersetzt werden, bilden ‚Befehle‘ für die ‚Arbeitsweise‘ wie z.B. ‚Start‘, ‚Stopp‘. Dieser ‚Kode‘ soll nach Duve ‚universal‘ für alle Lebewesen gelten. (vgl. S.66f)
[ANMERKUNG: Für eine vergleichende Lektüre zu diesem zentralen Vorgang der Proteinbildung sei empfohlen, die immer sehr aktuellen Versionen der entsprechenden englischsprachigen Wikipediabeiträge zu lesen (siehe unten Wkipedia (en).]
Duve weist ausdrücklich darauf hin, dass die eigentliche ‚Übersetzung‘, die eigentliche ‚Kodierung‘ außerhalb, vorab zu dem mRNA-tRNA Mechanismus liegt. Der ribosomale Konstruktionsprozess übernimmt ja einfach die Zuordnung von Antikodon und Aminosäure, wie sie die Transfer-RNA liefert. Wann, wie und wo kam es aber zur Kodierung von Antikodon und Aminosäure in dem Format, das dann schließlich zum ‚Standard‘ wurde? (vgl. S.69)
Letztlich scheint Duve an diesem Punkt auf der Stelle zu treten. Er wiederholt hier nur die Tatsachen, dass RNA-Moleküle mindestens in der dreifachen Funktionalität (Botschaft, Transfer und Konformal) auftreten können und dass sich diese drei Funktionen beim Zusammenbauen von Peptidketten ergänzen. Er projiziert diese Möglichkeit in die Vergangenheit als möglichen Erklärungsansatz, wobei diese reine Möglichkeit der Peptidwerdung keinen direkten ‚evolutionären Fitnesswert‘ erkennen lässt, der einen bestimmte Entwicklungsprozess steuern könnte.(vgl. S.69f) Er präzisiert weiter, dass der ‚Optimierung‘ darin bestanden haben muss, dass — in einer ersten Phase — ein bestimmtes Transfer-RNA Molekül hochspezifisch nur eine bestimmte Aminosäure kodiert. In einer nachfolgenden Phase konzentrierte sich die Optimierung dann auf die Auswahl der richtigen Boten-RNA. (vgl.S.70f)
[ANMERKUNG: Das alles ist hochspekulativ. Andererseits, die ‚Dunkelheit‘ des Entstehungsprozesses ist nicht ‚völlige Schwärze‘, sondern eher ein ’nebliges Grau‘, da man sich zumindest grundsätzlich Mechanismen vorstellen kann, wie es gewesen sein könnte.]
Duve reflektiert auch über mögliche chemische Präferenzen und Beschränkungen innerhalb der Bildung der Zuordnung (= Kodierung) von Kodons und Antikodons mit der Einschätzung, dass die fassbaren chemischen Eigenschaften darauf hindeuten, dass eine solche Zuordnung nicht ohne jede Beschränkung, sprich ’nicht rein zufällig‘ stattgefunden hat.(vgl. S.72f)
[ANMERKUNG: Der spekulative Charakter bleibt, nicht zuletzt auch deswegen, weil Duve schon für den ‚evolutionären‘ Charakter der Kodon-Antikodon Entwicklung das fiktive Konzept einer ‚Protozelle‘ voraussetzen muss, deren Verfügbarkeit vollständig im Dunkel liegt. Etwas kaum Verstandenes (= die Kodon-Antikodon Zuordnung) wird durch etwas an dieser Stelle vollständig Unverstandenes (= das Konzept der Protozelle) ‚erklärt‘. Natürlich ist dies keine echte Kritik an Duve; schließlich versucht er ja — und darin mutig — im Nebel der verfügbaren Hypothesen einen Weg zu finden, der vielleicht weiter führen könnte. In solchen unbefriedigenden Situationen wäre eine ‚vornehme Zurückhaltung‘ fehl am Platze; Suchen ist allemal gefährlich… ]
Duve geht jedenfalls von der Annahme aus, dass ein evolutionärer Prozess nur in dem Umfang effektiv einsetzen konnte, als die Veränderung der Kodon-Antikodon Zuordnung samt den daraus resultierenden chemischen Prozessen (Katalysen, Metabolismus…) insgesamt ein Trägersystem — in diesem Fall die vorausgesetzte Protozelle — ‚positiv‘ unterstützte und ‚überlebensfähiger‘ machte. (vgl. S.73f)
Ungeachtet der Schwierigkeit, die Details des Entstehungsprozesses zum jetzigen Zeitpunkt zu enthüllen, versucht Duve weitere Argumente zu versammeln, die aufgrund allgemeiner Eigenschaften des Entstehungsprozesses den evolutionären Charakter dieses Prozesses weiter untermauern.
Generell gehört es zu einem evolutionären Prozess, dass die Entwicklung zum Zeitpunkt t nur auf das zurückgreifen kann, was an Möglichkeiten zum Zeitpunkt t-1 zur Verfügung gestellt wird, also change: STATE —> STATE. Dies schränkt den Raum der Möglichkeiten grundsätzlich stark ein. (vgl. S.75, 77)
Da es bei der Übersetzung von mRNA in Peptide zu Fehlern kommen kann (Duve zitiert Eigen mit der quantitativen Angabe, dass auf 70 – 100 übersetzten Aminosäuren 1 Baustein falsch ist ), bedeutet dies dass die ersten Kodon-Antikodon Zuordnungen in Gestalt von mRNA Molekülen aufgrund dieser Fehlerrate nur 60 – 90 Einheiten lang sein konnten, also nur 20 – 30 Aminosäuren kodieren konnten. (vgl. S.76)
Rein kombinatorisch umfasst der Möglichkeitsraum bei 20 Aminosäuren 20^n viele Varianten, also schon bei einer Länge von nur 100 Aminosäuren 10^130 verschiedene Moleküle. Rein praktisch erscheint nach Duve ein solcher Möglichkeitsraum zu groß. Nimmt man hingegen an — was nach Duve der tatsächlichen historischen Situation eher entsprechen soll –, dass es zu Beginn nur 8 verschiedene Aminosäuren gab die zu Ketten mit n=20 verknüpft wurden, dann hätte man nur 8^20 = 10^18 Möglichkeiten zu untersuchen. In einem kleinen Tümpel (‚pond‘) erscheint das ‚Ausprobieren‘ von 10^18 Variationen nach Duve nicht unrealistisch.(vgl. S.76)
Schließlich führt Duve noch das Prinzip der ‚Modularität‘ ein: RNA-Moleküle werde nicht einfach nur ‚Elementweise‘ verlängert, sondern ganze ‚Blöcke‘ von erprobten Sequenzen werden kombiniert. Dies reduziert einserseits den kombinatorischen Raum drastisch, andererseits erhöht dies die Stabilität. (vgl. S.77)
Fortsetzung folgt…
LITERATURVERWEISE
Chaitin, G.J; Algorithmic information theory. Cambridge: UK, Cambridge University Press, (first:1987), rev.ed. 1988, 1990, 1992, ,paperback 2004
Noeth, W., Handbuch der Semiotik, 2. vollst. neu bearb. und erw. Aufl. mit 89 Abb. Stuttgart/Weimar: J.B. Metzler, xii + 668pp, 2000
Claude E. Shannon A mathematical theory of communication. Bell System Tech. J., 27:379-423, 623-656, July, Oct. 1948 (online: http://cm.bell-labs.com/cm/ms/what/shannonday/paper.html; zuletzt besucht: May-15, 2008)
Claude E. Shannon; Warren Weaver The mathematical theory of communication. Urbana – Chicgo: University of Illinois Press, 1948.
Das dritte Kapitel ist überschrieben ‚Out of the Slime‘. (SS.69-96) Es startet mit Überlegungen zur Linie der Vorfahren (Stammbaum), die alle auf ‚gemeinsame Vorfahren‘ zurückführen. Für uns Menschen zu den ersten Exemplaren des homo sapiens in Afrika vor 100.000 Jahren, zu den einige Millionen Jahre zurückliegenden gemeinsamen Vorläufern von Affen und Menschen; ca. 500 Mio Jahre früher waren die Vorläufer Fische, zwei Milliarden Jahre zurück waren es Mikroben. Und diese Rückführung betrifft alle bekannten Lebensformen, die, je weiter zurück, sich immer mehr in gemeinsamen Vorläufern vereinigen, bis hin zu den Vorläufern allen irdischen Lebens, Mikroorganismen, Bakterien, die die ersten waren.(vgl. S.69f)
[Anmerkung: Die Formulierung von einem ‚einzelnen hominiden Vorfahren‘ oder gar von der ‚afrikanischen Eva‘ kann den Eindruck erwecken, als ob der erste gemeinsame Vorfahre ein einzelnes Individuum war. Das scheint mir aber irreführend. Bedenkt man, dass wir ‚Übergangsphasen‘ haben von Atomen zu Molekülen, von Molekülen zu Netzwerken von Molekülen, von Molekülnetzwerken zu Zellen, usw. dann waren diese Übergänge nur erfolgreich, weil viele Milliarden und Abermilliarden von Elementen ‚gleichzeitig‘ beteiligt waren; anders wäre ein ‚Überleben‘ unter widrigsten Umständen überhaupt nicht möglich gewesen. Und es spricht alles dafür, dass dieses ‚Prinzip der Homogenität‘ sich auch bei den ‚komplexeren‘ Entwicklungsstufen fortgesetzt hat. Ein einzelnes Exemplar einer Art, das durch irgendwelche besonderen Eigenschaften ‚aus der Reihe‘ gefallen wäre, hätte gar nicht existieren können. Es braucht immer eine Vielzahl von hinreichend ‚ähnlichen‘ Exemplaren, dass ein Zusammenwirken und Fortbestehen realisiert werden kann. Die ‚Vorgänger‘ sind also eher keine spezifischen Individuen (wenngleich in direkter Abstammung schon), sondern immer Individuen als Mitglieder einer bestimmten ‚Art‘.]
Es ist überliefert, dass Darwin im Sommer 1837, nach der Rückkehr von seiner Forschungsreise mit der HMS Beagle in seinem Notizbuch erstmalig einen irregulär verzweigenden Baum gemalt hat, um die vermuteten genealogischen Zusammenhänge der verschiedenen Arten darzustellen. Der Baum kodierte die Annahme, dass letztlich alle bekannten Lebensformen auf einen gemeinsamen Ursprung zurückgehen. Ferner wird deutlich, dass viele Arten (heutige Schätzungen: 99%) irgendwann ‚ausgestorben‘ sind. Im Falle einzelliger Lebewesen gab es aber – wie wir heute zunehmend erkennen können – auch das Phänomene der Symbiose: ein Mikroorganismus ‚frißt‘ andere und ‚integriert‘ deren Leistung ‚in sich‘ (Beispiel die Mitochondrien als Teil der heute bekannten Zellen). Dies bedeutet, dass ‚Aussterben‘ auch als ‚Synthese‘ auftreten kann.(vgl. SS.70-75)
Die Argumente für den Zusammenhang auf Zellebene zwischen allen bekannten und ausgestorbenen Arten mit gemeinsamen Vorläufern beruhen auf den empirischen Fakten, z.B. dass die metabolischen Verläufe der einzelnen Zellen gleich sind, dass die Art und Weise der genetischen Kodierung und Weitergabe gleich ist, dass der genetische Kode im Detail der gleiche ist, oder ein kurioses Detail wie die molekulare Ausrichtung – bekannt als Chiralität –; obgleich jedes Molekül aufgrund der geltenden Gesetze sowohl rechts- oder linkshändig sein kann, ist die DNA bei allen Zellen ‚rechtshändig‘ und ihr Spiegelbild linkshändig. (vgl.SS.71-73)
Da das DNA-Molekül bei allen bekannten Lebensformen in gleicher Weise unter Benutzung von Bausteinen aus Aminosäure kodiert ist, kann man diese Moleküle mit modernen Sequenzierungstechniken Element für Element vergleichen. Unter der generellen Annahme, dass sich bei Weitergabe der Erbinformationen durch zufällige Mutationen von Generation zur Generation Änderungen ergeben können, kann man anhand der Anzahl der verschiedenen Elemente sowohl einen ‚genetischen Unterschied‘ wie auch einen ‚genealogischen Abstand‘ konstruieren. Der genetische Unterschied ist direkt ’sichtbar‘, die genaue Bestimmung des genealogischen Abstands im ‚Stammbaum‘ hängt zusätzlich ab von der ‚Veränderungsgeschwindigkeit‘. Im Jahr 1999 war die Faktenlage so, dass man annimmt, dass es gemeinsame Vorläufer für alles Leben gegeben hat, die sich vor ca. 3 Milliarden Jahren in die Art ‚Bakterien‘ und ‚Nicht-Bakterien‘ verzweigt haben. Die Nicht-Bakterien haben sich dann weiter verzweigt in ‚Eukaryoten‘ und ‚Archäen‘. (vgl. SS.75-79)
Davies berichtet von bio-geologischen Funden nach denen in de Nähe von Isua (Grönland) Felsen von vor mindestens -3.85 Milliarden Jahren gefunden wurden mit Spuren von Bakterien. Ebenso gibt es Funde von Stromatolythen (Nähe Shark Bay, Australien), mit Anzeichen für Cyanobakterien aus der Zeit von ca. -3.5 Milliarden Jahren und aus der gleichen Zeit Mikrofossilien in den Warrawoona Bergen (Australien). Nach den Ergebnissen aus 1999 hatten die Cyanobakterien schon -3.5 Mrd. Jahre Mechanismen für Photosynthese, einem höchst komplexen Prozess.(vgl. SS.79-81)
Die immer weitere Zurückverlagerung von Mikroorganismen in die Vergangenheit löste aber nicht das Problem der Entstehung dieser komplexen Strukturen. Entgegen der früher verbreiteten Anschauung, dass ‚Leben‘ nicht aus ‚toter Materie‘ entstehen kann, hatte schon Darwin 1871 in einem Brief die Überlegung geäußert, dass in einer geeigneten chemischen Lösung über einen hinreichend langen Zeitraum jene Moleküle und Molekülvernetzungen entstehen könnten, die dann zu den bekannten Lebensformen führen. Aber erst in den 20iger Jahren des 20.Jahrhunderts waren es Alexander Oparin (Rußland) und J.B.S.Haldane (England) die diese Überlegungen ernst nahmen. Statt einem kleinen See, wie bei Darwin, nahm Haldane an, dass es die Ozeane waren, die den Raum für den Übergangsprozess von ‚Materie‘ zu ‚Leben‘ boten. Beiden Forschern fehlten aber in ihrer Zeit die entscheidende Werkzeuge und Erkenntnisse der Biochemie und Molekularbiologie, um ihre Hypothesen testen zu können. Es war Harold Urey (USA) vorbehalten, 1953 mit ersten Laborexperimenten beginnen zu können, um die Hypothesen zu testen. (vgl. SS.81-86)
Mit Hilfe des Studenten Miller arrangierte Urey ein Experiment, bei dem im Glaskolben eine ‚Mini-Erde‘ bestehend aus etwas Wasser mit den Gasen Methan, Hydrogen und Ammonium angesetzt wurde. Laut Annahme sollte dies der Situation um ca. -4 Millarden Jahren entsprechen. Miller erzeugte dann in dem Glaskolben elektrische Funken, um den Effekt von Sonnenlicht zu simulieren. Nach einer Woche fand er dann verschiedene Amino-Säuren, die als Bausteine in allen biologischen Strukturen vorkommen, speziell auch in Proteinen.(vgl. S.86f)
Die Begeisterung war groß. Nachfolgende Überlegungen machten dann aber klar, dass damit noch nicht viel erreicht war. Die Erkenntnisse der Geologen deuteten in den nachfolgenden Jahren eher dahin, dass die Erdatmosphäre, die die sich mehrfach geändert hatte, kaum Ammonium und Methan enthielt, sondern eher reaktions-neutrales Kohlendioxyd und Schwefel, Gase die keine Aminosäuren produzieren. (vgl.S.87)
Darüber hinaus ist mit dem Auftreten von Aminosäuren als Bausteine für mögliche größere Moleküle noch nichts darüber gesagt, ob und wie diese größere Moleküle entstehen können. Genauso wenig wie ein Haufen Ziegelsteine einfach so ein geordnetes Haus bilden wird, genauso wenig formen einzelne Aminosäuren ‚einfach so‘ ein komplexes Molekül (ein Peptid oder Polypeptid). Dazu muss der zweite Hauptsatz überwunden werden, nach dem ’spontane‘ Prozesse nur in Richtung Energieabbau ablaufen. Will man dagegen komplexe Moleküle bauen, muss man gegen den zweiten Hauptsatz die Energie erhöhen; dies muss gezielt geschehen. In einem angenommenen Ozean ist dies extrem unwahrscheinlich, da hier Verbindungen eher aufgelöst statt synthetisiert werden.(vgl.87-90)
Der Chemiker Sidney Fox erweiterte das Urey-Experiment durch Zufuhr von Wärme. In der Tat bildeten sich dann Ketten von Aminosäurebausteinen die er ‚Proteinoide‘ nannte. Diese waren eine Mischung aus links- und rechts-händigen Molekülen, während die biologisch relevanten Moleküle alle links-händig sind. Mehr noch, die biologisch relevanten Aminosäureketten sind hochspezialisiert. Aus der ungeheuren Zahl möglicher Kombinationen die ‚richtigen‘ per Zufall zu treffen grenzt mathematisch ans Unmögliche.(vgl.S.90f) Dazu kommt, dass eine Zelle viele verschiedene komplexe Moleküle benötigt (neben Proteinen auch Lipide, Nukleinsäuren, Ribosomen usw.). Nicht nur ist jedes dieser Moleküle hochkomplex, sondern sie entfalten ihre spezifische Wirkung als ‚lebendiges Ensemble‘ erst im Zusammenspiel. Jedes Molekül ‚für sich‘ weiß aber nichts von einem Zusammenhang. Wo kommen die Informationen für den Zusammenhang her? (vgl.S.91f) Rein mathematisch ist die Wahrscheinlichkeit, dass sich die ‚richtigen‘ Proteine bilden in der Größenordnung von 1:10^40000, oder, um ein eindrucksvolles Bild des Physikers Fred Hoyle zu benutzen: genauso unwahrscheinlich, wie wenn ein Wirbelsturm aus einem Schrottplatz eine voll funktionsfähige Boeing 747 erzeugen würde. (vgl.S.95)
Die Versuchung, das Phänomen des Lebens angesichts dieser extremen Unwahrscheinlichkeiten als etwas ‚Besonderes‘, als einen extrem glücklichen Zufall, zu charakterisieren, ist groß. Davies plädiert für eine Erklärung als eines ’natürlichen physikalischen Prozesses‘. (S.95f)
Im Kapitel 4 ‚The Message in the Machine‘ (SS.97-122) versucht Davies mögliche naturwissenschaftliche Erklärungsansätze, beginnend bei den Molekülen, vorzustellen. Die Zelle selbst ist so ungeheuerlich komplex, dass noch ein Niels Bohr die Meinung vertrat, dass Leben als ein unerklärbares Faktum hinzunehmen sei (vgl.Anmk.1,S.99). Für die Rekonstruktion erinnert Davies nochmals daran, dass diejenigen Eigenschaften, die ‚lebende‘ Systeme von ’nicht-lebenden‘ Systemen auszeichnen, Makroeigenschaften sind, die sich nicht allein durch Verweis auf die einzelnen Bestandteile erklären lassen, sondern nur und ausschließlich durch das Zusammenspiel der einzelnen Komponenten. Zentrale Eigenschaft ist hier die Reproduktion. (vgl.SS.97-99)
Reproduktion ist im Kern gebunden an das Kopieren von drei-dimensional charakterisierten DNA-Molekülen. Vereinfacht besteht solch ein DNA-Molekül aus zwei komplementären Strängen, die über eine vierelementiges Alphabet von Nukleinsäurebasen miteinander so verbunden sind, dass es zu jeder Nukleinsäurebase genau ein passendes Gegenstück gibt. Fehlt ein Gegenstück, ist es bei Kenntnis des Kodes einfach, das andere Stück zu ergänzen. Ketten von den vierelementigen Basen können ‚Wörter‘ bilden, die ‚genetische Informationen‘ kodieren. Ein ‚Gen‘ wäre dann solch ein ‚Basen-Wort‘. Und das ganze Molekül wäre dann die Summe aller Gene als ‚Genom‘. Das ‚Auftrennen‘ von Doppelsträngen zum Zwecke des Kopierens wie auch das wieder ‚Zusammenfügen‘ besorgen spezialisierte andere Moleküle (Enzyme). Insgesamt kann es beim Auftrennen, Kopieren und wieder Zusammenfügen zu ‚Fehlern‘ (Mutationen) kommen. (vgl.SS.100-104)
Da DNA-Moleküle als solche nicht handlungsfähig sind benötigen sie eine Umgebung, die dafür Sorge trägt, dass die genetischen Informationen gesichert und weitergegeben werden. Im einfachen Fall ist dies eine Zelle. Um eine Zelle aufzubauen benötigt man Proteine als Baumaterial und als Enzyme. Proteine werden mithilfe der genetischen Informationen in der DNA erzeugt. Dazu wird eine Kopie der DNA-Informationen in ein Molekül genannt Boten-RNA (messenger RNA, mRNA) kopiert, dieses wandert zu einem komplexen Molekülnetzwerk genannt ‚Ribosom‘. Ribosomen ‚lesen‘ ein mRNA-Molekül als ‚Bauanleitung‘ und generieren anhand dieser Informationen Proteine, die aus einem Alphabet von 20 (bisweilen 21) Aminosäuren zusammengesetzt werden. Die Aminosäuren, die mithilfe des Ribosoms Stück für Stück aneinandergereiht werden, werden von spezialisierten Transportmolekülen (transfer RNA, tRNA) ‚gebracht‘, die so gebaut sind, dass immer nur dasjenige tRNA-Molekül andocken kann, das zur jeweiligen mRNA-Information ‚passt‘. Sobald die mRNA-Information ‚abgearbeitet‘ ist, liegt eines von vielen zehntausend möglichen Proteinen vor. (vgl.SS. 104-107) Bemerkenswert ist die ‚Dualität‘ der DNA-Moleküle (wie auch der mRNA) sowohl als ‚Material/ Hardware‘ wie auch als ‚Information/ Software‘. (vgl.S.108)
Diese ‚digitale‘ Perspektive vertieft Davies durch weitere Betrachtung und führt den Leser zu einem Punkt, bei dem man den Eindruck gewinnt, dass die beobachtbaren und messbaren Materialien letztlich austauschbar sind bezogen auf die ‚impliziten Strukturen‘, die damit realisiert werden. Am Beispiel eines Modellflugzeugs, das mittels Radiowellen ferngesteuert wird, baut er eine Analogie dahingehend auf, dass die Hardware (das Material) des Flugzeugs wie auch der Radiowellen selbst als solche nicht erklären, was das Flugzeug tut. Die Hardware ermöglicht zwar grundsätzlich bestimmte Flugeigenschaften, aber ob und wie diese Eigenschaften genutzt werden, das wird durch ‚Informationen‘ bestimmt, die per Radiowellen von einem Sender/ Empfänger kommuniziert werden. Im Fall einer Zelle bilden komplexe Molekülnetzwerke die Hardware mit bestimmten verfügbaren chemischen Eigenschaften, aber ihr Gesamtverhalten wird gesteuert durch Informationen, die primär im DNA-Molekül kodiert vorliegt und die als ‚dekodierte‘ Information alles steuert.(vgl. SS.113-115)
[Anmerkung: Wie schon zuvor festgestellt, repräsentieren Atome und Moleküle als solche keine ‚Information‘ ‚von sich aus‘. Sie bilden mögliche ‚Ereignisse‘ E ‚für andere‘ Strukturen S, sofern diese andere Strukturen S auf irgendeine Weise von E ‚beeinflusst‘ werden können. Rein physikalisch (und chemisch) gibt es unterschiedliche Einwirkungsmöglichkeiten (z.B. elektrische Ladungen, Gravitation,…). Im Falle der ‚Information‘ sind es aber nicht nur solche primären physikalisch-chemischen Eigenschaften, die benutzt werden, sondern das ‚empfangende‘ System S befindet sich in einem Zustand, S_inf, der es dem System ermöglicht, bestimmte physikalisch-chemische Ereignisse E als ‚Elemente eines Kodes‘ zu ‚interpretieren. Ein Kode ist minimal eine Abbildungsvorschrift, die Elemente einer Menge X (die primäre Ereignismenge) in eine Bildmenge Y (irgendwelche anderen Ereignisse, die Bedeutung) ‚übersetzt‘ (kodiert), also CODE: X —> Y. Das Materiell-Stoffliche wird damit zum ‚Träger von Informationen‘, zu einem ‚Zeichen‘, das von einem Empfänger S ‚verstanden‘ wird. Im Falle der zuvor geschilderten Replikation wurden ausgehend von einem DNA-Molekül (= X, Ereignis, Zeichen) mittels mRNA, tRNA und Ribosom (= Kode, CODE) bestimmte Proteine (=Y, Bedeutung) erzeugt. Dies bedeutet, dass die erzeugten Proteine die ‚Bedeutung des DNA-Moleküls‘ sind unter Voraussetzung eines ‚existierenden Kodes‘ realisiert im Zusammenspiel eines Netzwerkes von mRNA, tRNAs und Ribosom. Das Paradoxe daran ist, das die einzelnen Bestandteile des Kodes, die Moleküle mRNA, tRNA und Ribosom (letzteres selber hochkomplex) ‚für sich genommen‘ keinen Kode darstellen, nur in dem spezifischen Zusammenspiel! Wenn also die einzelnen materiellen Bestandteile, die Atome und Moleküle ‚für sich gesehen‘ keinen komplexen Kode darstellen, woher kommt dann die Information, die alle diese materiell hochkomplexen Bestandteile auf eine Weise ‚zusammenspielen‘ lässt, die weit über das hinausgeht, was die Bestandteile einzeln ‚verkörpern‘? ]
zelle_tm
[Anmerkung: Es gibt noch eine andere interssante Perspektive. Das mit Abstand wichtigste Konzept in der (theoretischen) Informatik ist das Konzept der Berechenbarkeit, wie es zunächst von Goedel 1931, dann von Turing in seinem berühmten Artikel von 1936-7 vorgelegt worden ist. In seinem Artikel definiert Turing das mathematische (!) Konzept einer Vorrichtung, die alle denkbaren berechenbaren Prozesse beschreiben soll. Später gaben andere dieser Vorrichtung den Namen ‚Turingmaschine‘ und bis heute haben alle Beweise immer nur dies eine gezeigt, dass es kein anderes formales Konzept der intuitiven ‚Berechenbarkeit‘ gibt, das ’stärker‘ ist als das der Turingmaschine. Die Turingmaschine ist damit einer der wichtigsten – wenn nicht überhaupt der wichtigste — philosophischen Begriff(e). Viele verbinden den Begriff der Turingmaschine oft mit den heute bekannten Computern oder sehen darin die Beschreibung eines konkreten, wenngleich sehr ‚umständlichen‘ Computers. Das ist aber vollständig an der Sache vorbei. Die Turingmaschine ist weder ein konkreter Computer noch überhaupt etwas Konkretes. Genau wie der mathematische Begriff der natürlichen Zahlen ein mathematisches Konzept ist, das aufgrund der ihm innewohnenden endlichen Unendlichkeit niemals eine reale Zahlenmenge beschreibt, sondern nur das mathematische Konzept einer endlich-unendlichen Menge von abstrakten Objekten, für die die Zahlen des Alltags ‚Beispiele‘ sind, genauso ist auch das Konzept der Turingmaschine ein rein abstraktes Gebilde, für das man konkrete Beispiele angeben kann, die aber das mathematische Konzept selbst nie erschöpfen (die Turingmaschine hat z.B. ein unendliches Schreib-Lese-Band, etwas, das niemals real existieren kann).
]
[Anmerkung: Das Interessante ist nun, dass man z.B. die Funktion des Ribosoms strukturell mit dem Konzept einer Turingmaschine beschreiben kann (vgl. Bild). Das Ribosom ist jene Funktionseinheit von Molekülen, die einen Input bestehend aus mRNA und tRNAs überführen kann in einen Output bestehend aus einem Protein. Dies ist nur möglich, weil das Ribosom die mRNA als Kette von Informationseinheiten ‚interpretiert‘ (dekodiert), die dazu führen, dass bestimmte tRNA-Einheiten zu einem Protein zusammengebaut werden. Mathematisch kann man diese funktionelle Verhalten eines Ribosoms daher als ein ‚Programm‘ beschreiben, das gleichbedeutend ist mit einer ‚Funktion‘ bzw. Abbildungsvorschrift der Art ‚RIBOSOM: mRNA x tRNA —> PROTEIN. Das Ribosom stellt somit eine chemische Variante einer Turingmaschine dar (statt digitalen Chips oder Neuronen). Bleibt die Frage, wie es zur ‚Ausbildung‘ eines Ribosoms kommen kann, das ’synchron‘ zu entsprechenden mRNA-Molekülen die richtige Abbildungsvorschrift besitzt.
]
Eine andere Blickweise auf das Phänomen der Information ist jene des Mathematikers Chaitin, der darauf aufmerksam gemacht hat, dass man das ‚Programm‘ eines Computers (sein Algorithmus, seine Abbildungsfunktion, seine Dekodierungsfunktion…) auch als eine Zeichenkette auffassen kann, die nur aus Einsen und Nullen besteht (also ‚1101001101010..‘). Je mehr Wiederholungen solch eine Zeichenkette enthalten würde, um so mehr Redundanz würde sie enthalten. Je weniger Wiederholung, um so weniger Redundanz, um so höher die ‚Informationsdichte‘. In einer Zeichenkette ohne jegliche Redundanz wäre jedes einzelne Zeichen wichtig. Solche Zeichenketten sind formal nicht mehr von reinen zufallsbedingten Ketten unterscheidbar. Dennoch haben biologisch nicht alle zufälligen Ketten eine ’nützliche‘ Bedeutung. DNA-Moleküle ( bzw. deren Komplement die jeweiligen mRNA-Moleküle) kann man wegen ihrer Funktion als ‚Befehlssequenzen‘ als solche binär kodierten Programme auffassen. DNA-Moleküle können also durch Zufall erzeugt worden sein, aber nicht alle zufälligen Erzeugungen sind ’nützlich‘, nur ein verschwindend geringer Teil. Dass die ‚Natur‘ es geschafft hat, aus der unendlichen Menge der nicht-nützlichen Moleküle per Zufall die herauszufischen, die ’nützlich‘ sind, geschah einmal durch das Zusammenspiel von Zufall in Gestalt von ‚Mutation‘ sowie Auswahl der ‚Nützlichen‘ durch Selektion. Es stellt sich die Frage, ob diese Randbedingungen ausreichen, um das hohe Mass an Unwahrscheinlichkeit zu überwinden. (vgl. SS. 119-122)
[Anmerkung: Im Falle ‚lernender‘ Systeme S_learn haben wir den Fall, dass diese Systeme einen ‚Kode‘ ‚lernen‘ können, weil sie in der Lage sind, Ereignisse in bestimmter Weise zu ‚bearbeiten‘ und zu ’speichern‘, d.h. sie haben Speichersysteme, Gedächtnisse (Memory), die dies ermöglichen. Jedes Kind kann ‚lernen‘, welche Ereignisse welche Wirkung haben und z.B. welche Worte was bedeuten. Ein Gedächtnis ist eine Art ‚Metasystem‘, in dem sich ‚wahrnehmbare‘ Ereignisse E in einer abgeleiteten Form E^+ so speichern (= spiegeln) lassen, dass mit dieser abgeleiteten Form E^+ ‚gearbeitet‘ werden kann. Dies setzt voraus, dass es mindestens zwei verschiedene ‚Ebenen‘ (layer, level) im Gedächtnis gibt: die ‚primären Ereignisse‘ E^+ sowie die möglichen ‚Beziehungen‘ RE, innerhalb deren diese vorkommen. Ohne dieses ‚Beziehungswissen‘ gibt es nur isolierte Ereignisse. Im Falle multizellulärer Organismen wird diese Speicheraufgabe durch ein Netzwerk von neuronalen Zellen (Gehirn, Brain) realisiert. Der einzelnen Zelle kann man nicht ansehen, welche Funktion sie hat; nur im Zusammenwirken von vielen Zellen ergeben sich bestimmte Funktionen, wie z.B. die ‚Bearbeitung‘ sensorischer Signale oder das ‚Speichern‘ oder die Einordnung in eine ‚Beziehung‘. Sieht man mal von der spannenden Frage ab, wie es zur Ausbildung eines so komplexen Netzwerkes von Neuronen kommen konnte, ohne dass ein einzelnes Neuron als solches ‚irgend etwas weiß‘, dann stellt sich die Frage, auf welche Weise Netzwerke von Molekülen ‚lernen‘ können. Eine minimale Form von Lernen wäre das ‚Bewahren‘ eines Zustandes E^+, der durch ein anderes Ereignis E ausgelöst wurde; zusätzlich müsste es ein ‚Bewahren‘ von Zuständen geben, die Relationen RE zwischen primären Zuständen E^+ ‚bewahren‘. Solange wir es mit frei beweglichen Molekülen zu tun haben, ist kaum zu sehen, wie es zu solchen ‚Bewahrungs-‚ sprich ‚Speicherereignissen‘ kommen kann. Sollte es in irgend einer Weise Raumgebiete geben, die über eine ‚hinreichend lange Zeit‘ ‚konstant bleiben, dann wäre es zumindest im Prinzip möglich, dass solche ‚Bewahrungsereignisse‘ stattfinden. Andererseits muss man aber auch sehen, dass diese ‚Bewahrungsereignisse‘ aus Sicht eines möglichen Kodes nur möglich sind, wenn die realisierenden Materialien – hier die Moleküle bzw. Vorstufen zu diesen – physikalisch-chemische Eigenschaften aufweisen, die grundsätzlich solche Prozesse nicht nur ermöglichen, sondern tendenziell auch ‚begünstigen‘, und dies unter Berücksichtigung, dass diese Prozesse ‚entgegen der Entropie‘ wirken müssen. Dies bedeutet, dass — will man keine ‚magischen Kräfte‘ annehmen — diese Reaktionspotentiale schon in den physikalisch-chemischen Materialien ‚angelegt‘ sein müssen, damit sie überhaupt auftreten können. Weder Energie entsteht aus dem Nichts noch – wie wir hier annehmen – Information. Wenn wir also sagen müssen, dass sämtliche bekannte Materie nur eine andere Zustandsform von Energie ist, dann müssen wir vielleicht auch annehmen, dass alle bekannten ‚Kodes‘ im Universum nichts anderes sind als eine andere Form derjenigen Information, die von vornherein in der Energie ‚enthalten‘ ist. Genauso wie Atome und die subatomaren Teilchen nicht ’neutral‘ sind sondern von vornherein nur mit charakteristischen (messbaren) Eigenschaften auftreten, genauso müsste man dann annehmen, dass die komplexen Kodes, die wir in der Welt und dann vor allem am Beispiel biologischer Systeme bestaunen können, ihre Wurzeln in der grundsätzlichen ‚Informiertheit‘ aller Materie hat. Atome formieren zu Molekülen, weil die physikalischen Eigenschaften sie dazu ‚bewegen‘. Molkülnetzwerke entfalten ein spezifisches ‚Zusammenspiel‘, weil ihre physikalischen Eigenschaften das ‚Wahrnehmen‘, ‚Speichern‘ und ‚Dekodieren‘ von Ereignissen E in einem anderen System S grundsätzlich ermöglichen und begünstigen. Mit dieser Annahme verschwindet ‚dunkle Magie‘ und die Phänomene werden ‚transparent‘, ‚messbar‘, ‚manipulierbar‘, ‚reproduzierbar‘. Und noch mehr: das bisherige physikalische Universum erscheint in einem völlig neuen Licht. Die bekannte Materie verkörpert neben den bislang bekannten physikalisch-chemischen Eigenschaften auch ‚Information‘ von ungeheuerlichen Ausmaßen. Und diese Information ‚bricht sich selbst Bahn‘, sie ‚zeigt‘ sich in Gestalt des Biologischen. Das ‚Wesen‘ des Biologischen sind dann nicht die ‚Zellen als Material‘, das Blut, die Muskeln, die Energieversorgung usw., sondern die Fähigkeit, immer komplexer Informationen aus dem Universum ‚heraus zu ziehen, aufzubereiten, verfügbar zu machen, und damit das ‚innere Gesicht‘ des Universums sichtbar zu machen. Somit wird ‚Wissen‘ und ‚Wissenschaft‘ zur zentralen Eigenschaft des Universums samt den dazugehörigen Kommunikationsmechanismen.]
Einen Überblick über alle bisherigen Themen findet sich HIER
Zitierte Literatur:
Chaitin, G.J.Information, Randomness & Incompleteness, 2nd ed., World Scientific, 1990
Turing, A. M.On Computable Numbers with an Application to the Entscheidungsproblem. In: Proc. London Math. Soc., Ser.2, vol.42(1936), pp.230-265; received May 25, 1936; Appendix added August 28; read November 12, 1936; corr. Ibid. vol.43(1937), pp.544-546. Turing’s paper appeared in Part 2 of vol.42 which was issued in December 1936 (Reprint in M.DAVIS 1965, pp.116-151; corr. ibid. pp.151-154).
Interessante Links:
Ein Video in Youtube, das eine Rede von Pauls Davies dokumentiert, die thematisch zur Buchbesprechung passt und ihn als Person etwas erkennbar macht.
Paul Davies, The FIFTH MIRACLE: The Search for the Origin and Meaning of Life, New York:1999, Simon & Schuster
Start: 20.Aug.2012
Letzte Fortsetzung: 26.Aug.2012
Mein Interesse an der Astrobiologie geht zurück auf das wundervolle Buch von Peter Ward und Donald Brownlee (2000) „Rare Earth: Why Complex Life is Uncommon in the Universe“. Obwohl ich zum Thema aus verschiedenen Gebieten schon einiges gelesen hatte war es doch dieses Buch, das all die verschiedenen Fakten für mich in einen Zusammenhang stellte, der das Phänomen ‚Leben‘ in einen größeren Zusammenhang erscheinen lies, der Zusammenhang mit der Geschichte des ganzen Universums. Dinge, die zuvor merkwürdig und ungereimt erschienen, zeigten sich in einem neuen Licht. Neben anderen Büchern war es dann das berühmte Büchlein „What Is Life?“ von Erwin Schroedinger (1944), das half, manche Fragen zu verschärfen Neben anderen Publikationen fand ich hier das Buch von von Horst Rauchfuß (2005) „Chemische Evolution und der Ursprung des Lebens“ sehr erhellend (hatte früher dazu andere Bücher gelesen wie z.B. Manfred Eigen (1993, 3.Aufl.) „Stufen zum Leben. Die frühe Evolution im Visier der Molekularbiologie“). Einen weiteren Schub erhielt die Fragestellung durch das – nicht so gut lesbare, aber faktenreiche – Buch von J. Gale (2009) „Astrobiology of Earth: The Emergence, Evolution and Future of Life on a Planet in Turmoil“. Gegenüber ‚Rare Earth‘ ergibt es keine neuen grundsätzlichen Erkenntnisse, wohl aber viele aktuelle Ergänzungen und z.T. Präzisierungen. Dass ich bei diesem Sachstand dann noch das Buch von Paul Davies gelesen habe, war eher systematische Neugierde (parallel habe ich noch angefangen Christian de Duve (1995) „Vital Dust. The origin and Evolution of Life on Earth“ sowie Jonathan I.Lunine (2005) „Astrobiology. A multidisciplinary Approach“).
Der Titel des Buchs „Das fünfte Wunder“ (The 5th Miracle) wirkt auf den ersten Blick leicht ‚esoterisch‘ und für sachlich orientierte Leser daher eher ein wenig abschreckend, aber Paul Davies ist ein angesehener Physiker und hat hier ein Buch geschrieben, das auf der Basis der Physik und Chemie die grundlegende Frage zum Ursprung und der Bedeutung des Lebens systematisch und spannend aufrollt. Hier wird man nicht einfach mit Fakten überschüttet (obgleich er diese hat), sondern anhand von Beobachtungen, daraus sich ergebenden Fragen und Hypothesen beschreibt er einen gedanklichen Prozess, der über Fragen zu Antworten führt, die wiederum neue Fragen entstehen lassen. Es gibt wenige wissenschaftliche Bücher, die so geschrieben sind. Ich halte es für ein glänzendes Buch, wenngleich manche Hypothesen sich durch die weitere Forschung als nicht so ergiebig erwiesen haben. Seine grundsätzlichen Überlegungen bleiben davon unberührt.
Den leicht irritierenden Titel erklärt Davies auf S.22 als Anspielung auf den biblischen Schöpfungsbericht, wo in Vers 11 vom ersten Buch Mose (= Buch Genesis) (abgekürzt Gen 1:11) beschrieben wird, dass Gott die Pflanzen geschaffen habe. Nach Davies war dies das fünfte Wunder nachdem zuvor laut Davies das Universeum (universe), das Licht (light), der Himmel (firmament) und das trockene Land (dry land) geschaffen worden seien. Einer bibelwissenschaftlichen Analyse hält diese einfache Analyse von Davies sicher nicht stand. Sie spielt auch für den gesamten restlichen Text überhaupt keine Rolle. Von daher erscheint mir dieser Titel sehr unglücklich und wenig hilfreich. Für mich beschreibt der Untertitel des Buches den wahren Inhalt am besten: „Die Suche nach dem Ursprung und der Bedeutung des Lebens“.
Im Vorwort (Preface, pp.11-23) formuliert Davies seine zentralen Annahmen. Mit einfachen Worten könnte man es vielleicht wie folgt zusammen fassen: Das Phänomen des Lebens zu definieren bereitet große Schwierigkeiten. Es zu erklären übersteigt die bisher bekannten physikalischen Gesetze. Dass Leben irgendwann im Kosmos aufgetreten ist und der ungefähre Zeitraum wann, das ist Fakt. Nicht klar ist im Detail, wie es entstehen konnte. Ferner ist nicht klar, ob es ein außergewöhnlicher Zufall war oder ob es im Raum der physikalischen Möglichkeiten einen favorisierten Pfad gibt, der durch die ‚inhärenten‘ Eigenschaften von Energie (Materie) dies ‚erzwingt‘. Nur im letzteren Fall wäre es sinnvoll, anzunehmen, dass Leben überall im Universum entstehen kann und – höchstwahrscheinlich – auch entstanden ist.
Dies sind dürre trockene Worte verglichen mit dem Text von Davies, der mit den zentralen Aussagen auch gleich ein bischen Forschungs- und Ideengeschichte rüberbringt (verwoben mit seiner eigenen Lerngeschichte) und der einen exzellenten Schreibstil hat (von daher kann ich jedem nur empfehlen, das Buch selbst zu lesen).
Für Davies ist die Frage der Entstehung des Lebens (Biogenese, engl. Biogenesis) nicht ‚irgend ein anderes‘ Problem, sondern repräsentiert etwas ‚völlig Tieferes‘, das die Grundlagen der gesamten Wissenschaft und des gesamten Weltbildes herausfordert (vgl. S.18). Eine Lösung verlangt radikal neue Ideen, neue Ansätze gegenüber dem Bisherigen (vgl. S.17). Das Phänomen des Lebens entzieht sich eindeutig dem zweiten Hauptsatz der Thermodynamik (der einen Ausgleich aller Energieunterschiede impliziert) und seine Besonderheiten ergeben sich nicht einfach durch bloßen Aufweis seiner chemischen Bestandteile (vgl. S.19). Er vermutet die Besonderheit des Phänomen Lebens in der ‚Organisation von Information‘, was dann die Frage aufwirft, wo diese Information herkommt (vgl.S.19). Als informationsgetriebene Objekte entziehen sich die Phänomene des Lebens allen bekannten Gesetzen der Physik und Chemie (und der Biologie, sofern sie diesen Aspekt nicht als Leitthema hat?).
Davies zieht aus diesen Annahmen den Schluß, dass kein bekanntes Naturgesetz solche hochkomplexe Strukturen von zusammenhanglosen chemischen Bestandteilen induzieren konnte. Er sieht in dem ganzen Entstehungsprozess ein ‚atemberaubendes geniales (ingeniuos)‘ lebens-freundliches Universum, das zu verstehen, wir ganz am Anfang stehen. (vgl. S.20).
Dass Davies aufgrund der atemberaubenden Komplexität von lebensfreundlichen Strukturen eine Interaktion der Erde mit anderen Planeten (z.B. dem Mars) in früheren Phasen nicht ausschließt und im weiteren Verlauf auch akribisch das Für und Wider untersucht, sei hier nur angemerkt. Ein eindeutiges Ergebnis gibt es aufgrund der komplizierten Zusammenhänge – soweit ich sehe – bis heute nicht. Ob spezielle Moleküle, die Bestandteile von lebenskonstituierenden Strukturen geworden sind, teilweise von außerhalb der Erde gekommen sind oder nicht, berührt die wichtigen Grundfragen nach der Struktur und der ‚Bedeutung‘ von Leben im Universum nicht.
Das erste Kapitel (SS.25-47) überschreibt er mit ‚Die Bedeutung des Lebens‘. Er beginnt nochmals mit der Feststellung, dass die Wissenschaft bislang nicht mit Sicherheit weiß, wie das Phänomen des Lebens tatsächlich begann (auf der Erde? mit Unterstützung aus dem Weltall,… ?)(vgl. S.26), um dann nochmals an die bekannten Fakten zu erinnern, wann in der zurückliegenden Zeit Lebensphänomene dokumentiert sind: das älteste gut dokumentierte Tierfossil datiert auf -560 Mio Jahren und findet sich in Australien (Flinders Ranges, nördlich von Adelaide). Etwa 15 Mio Jahre später findet man eine Artenexplosion, die vom Meer ausgehend das Land mit Pflanzen und Tieren ‚kolonisierte‘. Davor aber, ab etwa -1 Milliarde Jahre rückwärts, gab es nur einzellige Organismen. Alle Evidenzen sprechen nach Davies dafür, dass alle späteren komplexen Lebensformen sich aus diesen einfachen, einzelligen Formen entwickelt haben.(vgl.S.29)
Von diesen einzelligen Lebewesen (‚Mikroorganismen‘, ‚Bakterien‘ genannt) weiß man, dass Sie seit mindestens -3.5 Milliarden Jahre existieren [Ergänzung, kein Zitat bei Davies: nach Christian de Duve gibt es auf der ganzen Erde aus allen Zeiten Ablagerungen von Mikroorganismen, die sich versteinert haben und als Stromatolithen Zeugnis geben von diesen Lebensformen, vgl. Duve S.4f] (vgl. S.45)(laut Davies kann ein Löffel Erde bester Qualität 10 Billionen (10*10^12) Mikroorganismen enthalten, die 10.000 verschiedene Arten repräsentieren!(vgl. S.45). Die Verbindungen zwischen den verschiedenen Lebensformen werden durch Vergleiche ihrer Biochemie (auch Metabolismus) und über ihr genetisches Material identifiziert.(vgl. S.46) Von den heute bekannten Mikroorganismen leben diejenigen, die den ältesten Formen von Mikroorganismen am ähnlichsten sind, in großen Meerestiefen am Fuße unterseeischer Vulkane.(vgl. S.47)
Zugleich weiß man nach Davies, dass die lebenden Zelle in ihrer Größe das komplexeste System darstellen, was wir Menschen kennen. (vgl.S.29) Und genau dies bereitet ihm Kopfzerbrechen: Wie ist es möglich, dass ‚geistlose Moleküle‘, die letztlich nur ihre unmittelbaren Nachbarn ’stoßen und ziehen‘ können, zu einer ingeniösen Kooperation zusammenfinden, wie sie eine lebende Zelle verkörpert? (vgl. S.30)
Welche Eigenschaften sind letztlich charakteristisch für eine lebende Zelle? Davies listet oft genannte Eigenschaften auf (Autonomie, Reproduktion, Metabolismus, Ernährung , Komplexität, Organisation, Wachstum und Entwicklung, Informationsgehalt, Hardware/ Software Einheit , Permanenz und Wechsel (vgl.SS.33-36)) und stellt dann fest, dass es offensichtlich keine einfache Eigenschaft ist, die ‚Lebendes‘ von ‚Nicht-Lebendem‘ trennt. (vgl. S.36) Auch scheint eine ‚rein mechanistische‘ Erklärung der chemischen Kausalketten nicht ausreichend zu sein. Es gibt das Moment der ‚Selbstbestimmung‘ (self-determination) bei jeder Zelle, eine Form von ‚Autonomie‘, die sich von keinen physikalischen Eigenschaften herleiten lassen.(vgl. S.33) Biologische Komplexität ist offensichtlich ‚instruierte Komplexität‘, die auf Information basiert (information-based). (vgl. S.31)
Damit würde sich andeuten, dass die beiden Eigenschaften ‚Metabolismus‘ und ‚Reproduktion‘ zwei Kerneigenschaften darstellen (vgl. S.36f), die sich in dem Vorstellungsmodell ‚Hardware (= Metabolismus)‘ und ‚Software (= Reproduktion)‘ wiederfinden.
An dieser Stelle lenkt Davies den Blick nochmals auf ein zentrales Faktum des ganzen Phänomen Lebens, auf das außergewöhnlichste Molekül, das wir kennen, bestehend aus vielen Milliarden sequentiell angeordneten Atomen, bezeichnet als Desoxyribonukleinsäure (deoxyribonucleic acid) (DNA), eine Ansammlung von ‚Befehlen‘, um damit Organismen (Pflanzen, Tiere inklusiv Menschen) ‚hervorbringen‘ zu können. Und dieses Molekül ist unvorstellbar alt, mindestens 3.5 Milliarden Jahre. (vgl. S.41)
Wenn Davies dann weiter schreibt, dass diese DNA die Fähigkeit hat, sich zu Vervielfältigen (to replicate) (vgl. S.41f), dann ist dies allerdings nicht die ganze Wahrheit, denn das Molekül als solches kann strenggenommen garnichts. Es benötigt eine spezifische Umgebung, damit ein Vervielfältigungsprozess einsetzen kann, an den sich dann ein höchst komplexer Umsetzungsprozeß anschliesst, durch den die DNA-Befehle in irgendwelche dynamischen organismischen Strukturen überführt werden. D.h. dieses ‚Wunder‘ an Molekül benötigt zusätzlich eine geeignete ebenfalls höchst komplexe Umgebung an ‚Übersetzern‘ und ‚Machern, die aus dem ‚Bauplan‘ (blueprint) ein lebendes Etwas generieren. Das zuvor von Davies eingeführte Begriffspaar ‚Hardware’/ ‚Software‘ wäre dann so zu interpretieren, dass die DNA eine Sequenz von Ereignissen ist, die als ‚Band‘ einer Turingmaschine einen möglichen Input darstellen und die Umgebung einer DNA wäre dann der ausführende Teil, der einerseits diese DNA-Ereignisse ‚lesen‘ kann, sie mittels eines vorgegebenen ‚Programms‘ ‚dekodiert‘ und in ‚Ausgabeereignisse‘ (Output) überführt. Folgt man dieser Analogie, dann ist der eigentliche ‚berechnende‘ Teil, die ‚rechnende Maschine‘ eine spezifisch beschaffene ‚Umgebung‘ eines DNA-Moleküls (COMPUTER_ENV)! In der ‚Natur‘ ist diese rechnende Maschine realisiert durch Mengen von spezifischen Molekülen, die miteinander so interagieren können, dass ein DNA-Molekül als ‚Input‘ eine Ereigniskette auslöst, die zum ‚Aufbau‘ eines Organismus führt (minimal einer einzelnen Zelle (COMPUTER_INDIVIDUAL)), der dann selbst zu einer ‚rechnenden Maschine‘ wird, also (vereinfacht) COMPUTER_ENV: DNA x ENV —> COMPUTER_INDIVIDUAL.
Die von Davies erwähnte Vervielfältigung (Replikation) wäre dann grob eine Abbildung entweder von einem individuellen System (COMPUTER_INDIVIDUAL) zu einem neuen DNA-Molekül, das dann wieder zu einem Organismus führen kann, oder – wie später dann weit verbreitet – von zwei Organismen, die ihre DNA-Informationen ‚mischen‘ zu einer neuen DNA, vereinfachend REPLICATION: COMPUTER_INDIVIDUAL [x COMPUTER_INDIVIDUAL] x ENV —> DNA.
Sobald in der Entwicklung des Lebens die Brücke von ‚bloßen‘ Molekülen zu einem Tandem aus (DNA-)Molekül und Übersetzer- und Bau-Molekülen – also COMPUTER_ENV und COMPUTER_INDIVUDAL — geschlagen war, ab dann begann die ‚biologische Evolution‘ (wie Darwin und Vorläufer) sie beschrieben haben ‚zu laufen‘. Dieser revolutionäre Replikationsmechanismus mit DNA-Molekülen als Informationsformat wurde zum Generator aller Lebensformen, die wir heute kennen. (vgl.S.42)
Aus der Kenntnis dieses fundamentalen Replikationsmechanismus folgt aber keinerlei Hinweis, wie es zu diesem hochkomplexen Mechanismus überhaupt kommen konnte, und das vor mehr als 3.5 Milliarden Jahren irgendwo unter der Erdoberfläche [Eigene Anmerkung: eine Frage, die auch im Jahr 2012 noch nicht voll befriedigend beantwortet ist!]. (vgl.S.44)
Im Kapitel 2 ‚Against the Tide‘ (S.49-67) greift Davies nochmals den Aspekt des zweiten Hauptsatzes der Thermodynamik auf, nachdem in einem geschlossenen System die Energie erhalten bleibt und vorhandene Ungleichheiten in der Verteilung der Energie (geringere Entropie, geringere Unordnung = höhere Ordnung) auf Dauer ausgeglichen werden, bis eine maximale Gleichverteilung vorliegt (maximale Entropie, maximale Unordnung, minimale Ordnung). [Anmerkung: Dies setzt implizit voraus, dass Energieverdichtungen in einer bestimmten Region des geschlossenen Systems prinzipiell ‚auflösbar‘ sind. Materie als einer Zustandsform von Energie realisiert sich (vereinfacht) über Atome und Verbindungen von Atomen, die unter bestimmten Randbedingungen ‚auflösbar‘ sind. Verbindungen von Atomen speichern Energie und stellen damit eine höhere ‚Ordnung‘ dar als weniger verbundene Atome.]
Wie oben schon festgestellt, stellt die Zusammenführung von Atomen zu komplexen Molekülen, und eine Zusammenfügung von Molekülen zu noch komplexeren Strukturen, wie sie das Phänomen des Lebens auszeichnet, lokal begrenzt eine ‚Gegenbewegung‘ zum Gesetz der Zunahme von Entropie dar. Das Phänomen des Lebens widersetzt sich darin dem allgemeinen Trend (‚against the tide‘). Dies ist nur möglich, weil die biologischen Strukturen (Moleküle, Molekülverbände, Zellen, Replikation…) für ihre Zwecke Energie einsetzen! Dies bedeutet, sie benötigen ‚frei verfügbare Energie‘ (free energy) aus der Umgebung. Dies sind entweder Atomverbindungen, deren Energie sich mittels eines geringen Energieaufwandes teilweise erschließen lässt (z.B. Katalyse mittels Enzymen), oder aber die Nutzung von ‚Wärme‘ (unterseeische Vulkane, Sonnenlicht,…). Letztlich ist es die im empirischen Universum noch vorhandene Ungleichverteilungen von Energie, die sich partiell mit minimalem Aufwand nutzen lässt, die biologische Strukturen ermöglicht. Aufs Ganze gesehen führt die Existenz von biologischen Strukturen auf Dauer aber doch auch zum Abbau eben dieser Ungleichheiten und damit zum Anwachsen der Entropie gemäß dem zweiten Hauptsatz. (vgl. 49-55) [Anmerkung: durch fortschreitende Optimierungen der Energienutzungen (und auch der organismischen Strukturen selbst) kann die Existenz von ‚Leben‘ im empirischen Universum natürlich ’sehr lange‘ andauern.]
Davies weist an dieser Stelle ausdrücklich darauf hin, dass die scheinbare Kompatibilität des Phänomens Leben mit dem zweiten Hauptsatz der Thermodynamik nicht bedeutet, dass die bekannten Gesetze der Physik damit auch schon ‚erklären‘ würden, wie es überhaupt zur Ausbildung solcher komplexer Ordnungen im Universum kommen kann, wie sie die biologischen Strukturen darstellen. Sie tun es gerade nicht.(vgl. S.54) Er zitiert hier u.a. auch Erwin Schroedinger mit den Worten ‚Wir müssen damit rechnen, einen neuen Typ von physikalischem Gesetz zu finden, das damit klarkommt‘(vgl. S.52)
Davies macht hier auch aufmerksam auf die strukturelle Parallelität zwischen dem physikalischen Begriff der Entropie, dem biologischen Begriff der Ordnung und dem von Shannon geprägten Begriff der Information. Je mehr ‚Rauschen‘ (noise) wir in einer Telefonverbindung haben, um so weniger können wir die gesprochenen Worte des Anderen verstehen. Rauschen ist ein anderes Wort für ‚Unordnung = Entropie‘. Je geringer die Entropie heißt, d.h. umso höher die ‚Ordnung‘ ist, um so höher ist der Informationsgehalt für Sender und Empfänger. Shannon hat daher ‚Information‘ als ‚Negentropie‘, als ’negative Entropie‘ definiert. Biologische ‚Ordnung‘ im Sinne von spezifisch angeordneten Atomen und Molekülen würde im Sinne der Shannonschen Informationstheorie dann einen hohen Informationsgehalt repräsentieren, wie überhaupt jede Form von Ordnung dann als ‚Information‘ aufgefasst werden kann, da diese sich von einer ‚gleichmachenden Unordnung‘ ‚abhebt‘.(vgl. S.56)
Wie kann aus einem Rauschen (Unordnung) Information (Ordnung) entstehen? Davies (im Einklang mit Schroedinger) weist darauf hin, dass die Ordnung aus der frei verfügbaren Energie aus der Umgebung stammt.(vgl. S.56f). Das DNA-Molekül repräsentiert in diesem Sinne als geordnete Struktur auch Information, die durch ‚Mutationen‘ (= Rauschen!) verändert werden kann. Es werden aber nur jene Organismen in einer bestimmten Umgebung überleben, deren in der DNA-gespeicherten Information für die jeweilige Umgebung ‚hinreichend gut‘ ist. D.h. in der Interaktion zwischen (DNA, Replikationsmechanismus, Umgebung) filtert die Umgebung jene Informationen heraus, die ‚geeignet‘ sind für eine fortdauernde Interaktion [Anmerkung: salopp könnte man auch sagen, dass die Umgebung (bei uns die Erde) sich genau jene biologischen Strukturen ‚heranzüchtet‘, die für eine Kooperation ‚geeignet‘ sind, alle anderen werden aussortiert.](vgl. S.57)
Ein anderer Aspekt ist der Anteil an ‚Fehlern‘ in der DNA-Bauanleitung bzw. während des Replikationsprozesses. Ab einem bestimmten Anteil können Fehler einen funktionstüchtigen Organismus verhindern. Komplexe Organismen setzen entsprechend leistungsfähige Fehlervermeidungsmechanismen voraus. (vgl. SS.58-60)
Weiterhin ist zu beachten, dass ‚Information‘ im Sinne von Shannon eine rein statistische Betrachtung von Wahrscheinlichkeiten im Auftreten von bestimmten Kombinationen von Elementen einer Grundmenge darstellt. Je ’seltener‘ eine Konfiguration statistisch auftritt, umso höher ist ihr Informationsgehalt (bzw. ‚höhere Ordnungen‘ sind ’seltener‘). Dies Betrachtungsweise lässt die Dimension der ‚Bedeutung‘ ganz außer Acht.
Eine Bedeutung liegt immer dann vor, wenn ein Sender/ Empfänger von einer Entität (z.B. von einem DNA-Molekül oder von einem Abschnitt eines DNA-Moleküls) auf eine andere Entität (z.B. anderen Molekülen) ’schließen‘ kann. Im Falle der biologischen Strukturen wäre dies z.B. der Zusammenhang zwischen einem DNA-Molekül und jenen organismischen Strukturen, die aufgrund der Information im DNA-Molekül ‚gebaut‘ werden sollen. Diese zu bauenden organismischen Strukturen würden dann die ‚Bedeutung‘ darstellen, die mit einem DNA-Molekül zu verbinden wäre.
Shannonsche Information bzw. biologische Ordnung haben nichts mit dieser ‚(biologischen) Bedeutung‘ zu tun. Die biologische Bedeutung in Verbindung mit einem DNA-Molekül wäre damit in dem COMPUTER_ENV zu lokalisieren, der den ‚Input‘ DNA ‚umsetzt/ verwandelt/ übersetzt/ transformiert…‘ in geeignete biologische Strukturen.(vgl.S.60) [Anmerkung: Macht man sich hier die Begrifflichkeit der Semiotik zunutze, dann könnte man auch sagen, dass die spezifische Umgebung COMPUTER_ENV eine semiotische Maschine darstellt, die die ‚Syntax‘ der DNA übersetzt in die ‚Semantik‘ biologischer Organismen. Diese semiotische Maschine des Lebens ist ‚implementiert‘ als ein ‚chemischer Computer‘, der mittels diverser chemischer Reaktionsketten arbeitet, die auf den Eigenschaften unterschiedlicher Moleküle und Umgebungseigenschaften beruhen.]
Mit den Begriffen ‚Entropie‘, ‚Ordnung‘ und ‚Information‘ erwächst unweigerlich die Frage, wie konnte Ordnung bzw. Information im Universum entstehen, wo doch der zweite Hauptsatz eigentlich nur die Entropie favorisiert? Davies lenkt den Blick hier zurück auf den Ursprung des bekannten Universums und folgt dabei den Eckwerten der Big-Bang Theorie, die bislang immer noch die überzeugendste empirische Beschreibung liefert. In seiner Interpretation fand zu Beginn eine Umwandlung von Energie sowohl in die uns bekannte ‚Materie‘ statt (positive Energie), zugleich aber auch in ‚Gravitation‘ (negative Energie). Beide Energien heben sich gegenseitig auf. (vgl. S.61f)
Übernimmt man die übliche Deutung, dass die ‚kosmische Hintergrundstrahlung‘ einen Hinweis auf die Situation zu Beginn des Universums liefert, dann war das Universum zu Beginn ’nahezu strukturlos‘, d.h. nahe bei der maximalen Entropie, mit einer minimale Ordnung, nahezu keiner Information. (vgl. S.62f) Wie wir heute wissen, war es dann die Gravitation, die dazu führte, dass sich die fast maximale Entropie schrittweise abbaute durch Bildung von Gaswolken und dann von Sternen, die aufgrund der ungeheuren Verdichtung von Materie dann zur Rückverwandlung von Materie in Energie führte, die dann u.a. als ‚freie Energie‘ verfügbar wurde. [Anmerkung: der andere Teil führt zu Atomverbindungen, die energetisch ‚höher aufgeladen‘ sind. Diese stellt auch eine Form von Ordnung und Information dar, also etwa INF_mat gegenüber der INF_free.] Davies sieht in dieser frei verfügbare Energie die Quelle für Information. (vgl. S.63)
Damit wird auch klar, dass der zweite Hauptsatz der Thermodynamik nur eine Seite des Universums beschreibt. Die andere Seite wird von der Gravitation bestimmt, und diese arbeitet der Entropie diametral entgegen. Weil es die Gravitation gibt, gibt es Ordnung und Information im Universum. Auf dieser Basis konnten und können sich biologische Strukturen entwickeln. (vgl. S.64)
[Anmerkung: In dieser globalen Perspektive stellt die Biogenese letztlich eine folgerichtige Fortsetzung innerhalb der ganzen Kosmogenese dar. Aktuell bildet sie die entscheidende Phase, in der die Information als freie Energie die Information als gebundene Energie zu immer komplexeren Strukturen vorantreibt, die als solche einer immer mehr ‚verdichtete‘ (= komplexere) Information verkörpern. Biologische Strukturen bilden somit eine neue ‚Zustandsform‘ von Information im Universum.]
Mit den Augen der Quantenphysik und der Relativitätstheorie zeigt sich noch ein weiterer interessanter Aspekt: die einzelnen Teilchen, aus denen sich die bekannte Materie konstituiert, lassen ‚an sich‘, ‚individuell‘ keine ‚Kontexte‘ erkennen; jedes Teilchen ist wie jedes andere auch. Dennoch ist es so, dass ein Teilchen je nach Kontext etwas anderes ‚bewirken‘ kann. Diese ‚Beziehungen‘ zwischen den Teilchen, charakterisieren dann ein Verhalten, das eine Ordnung bzw. eine Information repräsentieren kann. D.h. Ordnung bzw. Information ist nicht ‚lokal‘, sondern eine ‚globale‘ Eigenschaft. Biologische Strukturen als Repräsentanten von Information einer hochkomplexen Art sind von daher wohl kaum durch physikalische Gesetze beschreibbar, die sich auf lokale Effekte beschränken. Man wird sicher eine neue Art von Gesetzen benötigen. (vgl. S.67)
[Anmerkung: Eine strukturell ähnliche Situation haben wir im Falle des Gehirns: der einzelnen Nervenzelle im Verband von vielen Milliarden Zellen kann man als solche nicht ansehen, welche Funktion sie hat. Genauso wenig kann man einem einzelnen neuronalen Signal ansehen, welche ‚Bedeutung‘ es hat. Je nach ‚Kontext‘ kann es von den Ohren kommen und einen Aspekt eines Schalls repräsentieren, oder von den Augen, dann kann es einen Aspekt des Sehfeldes repräsentieren, usw. Dazu kommt, dass durch die immer komplexere Verschaltung der Neuronen ein Signal mit zahllosen anderen Signalen ‚vermischt‘ werden kann, so dass die darin ‚kodierte‘ Information ’semantisch komplex‘ sein kann, obgleich das Signal selbst ‚maximal einfach‘ ist. Will man also die ‚Bedeutung‘ eines neuronalen Signals verstehen, muss man das gesamte ‚Netzwerk‘ von Neuronen betrachten, die bei der ‚Signalverarbeitung‘ zusammen spielen. Und das würde noch nicht einmal ausreichen, da der komplexe Signalfluss als solcher seine eigentliche ‚Bedeutung‘ erst durch die ‚Wirkungen im Körper‘ ‚zeigt‘. Die Vielzahl der miteinander interagierenden Neuronen stellen quasi nur die ‚Syntax‘ eines neuronalen Musters dar, dessen ‚Bedeutung‘ (die semantische Dimension) in den vielfältigen körperlichen Prozessen zu suchen ist, die sie auslösen bzw. die sie ‚wahrnehmen‘. Tatsächlich ist es sogar noch komplexer, da für die ‚handelnden Organismen‘ zusätzlich noch die ‚Umgebung‘ (die Außenwelt zum Körper) berücksichtigen müssen.]
Davies erwähnt im Zusammenhang der Gravitation als möglicher Quelle für Information auch Roger Penrose und Lee Smolin. Letzterer benutzt das Konzept der ‚Selbstorganisation‘ und sieht zwischen der Entstehung von Galaxien und biologischen Populationen strukturelle Beziehungen, die ihn zum Begriff der ‚eingebetteten Hierarchien von selbstorganisierenden Systemen führen. (vgl. S.65)
(1) Der Mensch ist durch seinen Körper primär ein animalisches Wesen, ein Körper im Prozess der Körperwerdung als Teil des Biologischen.
(2) Dieser Körper zeigt Eigenschaften, Funktionen, die sich nicht aus den Bestandteilen des Körpers als solchen erklären lassen, sondern nur durch ihr Zusammenwirken (Emergenz) sowohl mit anderen Teilen des Körpers wie auch mit der umgebenden Körperwelt.
(3) Dies bedeutet,dass diese emergenten Eigenschaften und Funktionen eine wirkende Wirklichkeitsebene aufspannen, die als solche kein greifbares Objekt ist sondern nur als Veränderungsprozess (induziert Zeit) aufscheint.
(4) Eine Veränderung (Funktion) als solche ist kein Objekt, aber kann von einem intelligenten Wesen wahrgenommen und als bestimmbare Grösse gespeichert werden.
(5) Als erinnerbare Veränderung kann eine emergente Eigenschaft zu einem kognitiven Objekt in einem einzelnen Körper werden.
(6) Über symbolische Kommunikation kann solch ein kognitives Objekt bedingt kognitiv kopiert und damit verteilt werden.
(7) Die Gesamtheit der kognitiven Objekte (und ihre kommunizierten Kopien) können ein Gesamtbild ergeben von dem, was wir als ‚Welt‘ wahrnehmen, erkennen und kommunizieren.
(8) Das biologische System als kognitiver Agent kann einer Vielzahl von körpereigenen Prozessen unterliegen, die die Speicherung und Erinnerung kognitiver Objekte beeinflussen. Das kognitive Objekt hat von daher immer nur eine begrenzte Ähnlichkeit mit denjenigen emergenten Eigenschaften, die zur seiner Entstehung geführt haben (alltagssprachlich: viele Menschen unterliegen psychologischen Einstellungen wie ‚Eitelkeit‘, ‚Hochmut‘, ‚Arroganz‘, ‚Selbstfixierung‘, ‚Ängsten‘, ‚Minderwertigkeitsgefühlen‘, ‚diversen Süchten‘ usw., die in ihrer psychischen Kraft andere kognitive Wirkungsfaktoren so überlagern können, dass sie nahezu ‚blind‘ werden für das, was wirklich ist. Nach und nach, ohne dass die Betreffenden es merken, generiert ihre kognitive Maschinerie aufgrund dieser anderen Einflüsse ein ‚Bild von der Welt‘, das zunehmend ‚verzerrt‘, ‚falsch‘ ist. Die Möglichkeit, diese Verzerrungen ‚aus sich heraus‘ zu erkennen sind sehr ungünstig; wenn nicht starke Ereignisse aus der Umgebung diese Systeme aus ihrer negativen Schleife herausreißen (wie?). Die Systeme selbst finden sich ganz ‚toll‘, aber die kognitive Welt ‚in ihrem Kopf‘ ist nicht die Welt, wie sie sich jenseits ’störender psychologischer Tendenzen‘ zeigen kann und zeigt.
(9) Kognitive Agenten, deren Kommunikation stark verzerrenden Faktoren unterliegt und die innerhalb ihrer individuellen kognitiven Prozesse die Transformierung von Körper- und Aussenweltwahrnehmung ebenfalls verzerren, tendieren dazu, ein pathologisches Bild von sich und der umgebenden Welt aufzubauen, was sich immer mehr –und dann auch immer schneller– in einen verzerrten Zustand hineinbewegt, der dann diesem kognitiven Agenten immer weniger ‚hilft‘ und immer mehr ’schadet‘ (Selbstzerstörung durch verzerrtes Wahrnehmen und Denken).
(10) Aus diesem Blickwinkel erscheint die sogenannte moderne Informationsgesellschaft nicht nur als rein positiver Raum sondern auch potentiell sehr gefährlich, da die Verbreitung von verzerrten kognitiven Objekten leicht ist und die kommerzielle Nutzung von von verzerrten kognitiven Objekten in der Regel einfacher und gewinnbringender ist als umgekehrt. Daraus würde folgen, dass überwiegend ‚geldorientierte‘ Informationsgesellschaften sich im Laufe der Zeit selbst kognitiv so ‚zumüllen‘, dass die wenigen nichtverzerrten kognitiven Objekte immer weniger auffindbar sein werden. Es entsteht ein Raum mit kognitiven Objekte, der als solcher verzerrt ist, korrespondierend sind aber auch alle kognitiven Räume in den Körpern der kognitiven Agenten selbst ‚verzerrt‘. Dieser gesellschaftlich organisierten Dunkelheit zu entkommen ist für ein einzelnes kognitives System schwer bis unmöglich. Wohin immer es seine individuelle Wahrnehmung lenken will, es wird dann fast nur noch verzerrte kognitive Objekte vorfinden. Die Produktion von ‚Müll‘ ist halt so unendlich viel einfacher; man muss sich um nichts kümmern und man denkt und redet einfach so drauflos…..es ist doch sowieso egal…..(sagt sich die ‚Ethik des (kognitiven) Mülls‘). In einer ‚verzerrten Infomationsgesellschaft‘ fühlt sich keiner schuldig, aber alle produzieren faktisch den Müll mit, der sich in der Verzerrung selbst legitimiert.